Análisis de Modelos de Aprendizaje Automático (ML)
Publicado el: 28 de Febrero del 2022 - Jhonatan Montilla

Valores de Explicación de Características Shapley (SHAP)
En este caso práctico se profundizarán los conocimientos de los valores de explicación de características Shapley, mejor conocidos como SHAP, este tema había sido tratado en una anterior publicación de manera general, para revisar dicho artículo puede hacer clic en el enlace Funcionamiento del Aprendizaje Automático (Machine Learning), en este caso práctico utilizaremos un conjunto de datos que hace referencia algunos datos publicitarios el cual podrá descargar directamente desde nuestro repositorio haciendo clic aquí.
Como paso inicial, como en todos los análisis será necesario cargar las librerías necesarias.
from patsy import dmatrices
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
import pandas as pd
import xgboost
import shap
import warnings
warnings.filterwarnings("ignore")
data = pd.read_csv("advertising.csv")
data.columns = data.columns.map(lambda row: "_".join(row.lower().split(" ")))
data.head()
| daily_time_spent_on_site | age | area_income | daily_internet_usage | ad_topic_line | city | male | country | timestamp | clicked_on_ad | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 68.95 | 35 | 61830 | 256.1 | Cloned 5thgeneration orchestration | Wrightburgh | 0 | Tunisia | 2016-03-27 00:53:11 | 0 |
| 1 | 80.23 | 31 | 68440 | 193.8 | Monitored national standardization | West Jodi | 1 | Nauru | 2016-04-04 01:39:02 | 0 |
| 2 | 69.47 | 26 | 59790 | 236.5 | Organic bottom-line service-desk | Davidton | 0 | San Marino | 2016-03-13 20:35:42 | 0 |
| 3 | 74.15 | 29 | 54810 | 245.9 | Triple-buffered reciprocal time-frame | West Terrifurt | 1 | Italy | 2016-01-10 02:31:19 | 0 |
| 4 | 68.37 | 35 | 73890 | 225.6 | Robust logistical utilization | South Manuel | 0 | Iceland | 2016-06-03 03:36:18 | 0 |
Construcción del Modelo de Aprendizaje Automático
Se procederá a la construcción de un modelo de aprendizaje automático para que, a través del actual conjunto
de datos, predecir si un usuario hizo clic en un anuncio en función de alguna información sobre este. Se
utilizará la función damatrices() de la librería Patsy para convertir el
DataFrame de Pandas en una matriz de funciones o una matriz de valores objetivo.
y, X = dmatrices(
"clicked_on_ad ~ daily_time_spent_on_site + age + area_income + daily_internet_usage + male -1",
data = data,
)
X_frame = pd.DataFrame(data = X,
columns = X.design_info.column_names)
- Ahora, se procede a dividir el conjunto de datos en dos conjuntos, uno para entrenamiento y el otro para pruebas en proporción de 80% de los datos para entrenamiento y 20% para las pruebas.
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size = 0.2,
random_state = 7
)
- Haciendo uso de la función
XGBoost()se construirá el modelo para hacer las predicciones.
model = xgboost.XGBClassifier().fit(X_train, y_train)
predict = model.predict(X_test)
- Para evaluar el funcionamiento del modelo se utilizará la función
f1_score().
f1 = f1_score(y_test, predict)
f1
0.9619047619047619
Interpretación del funcionamiento del modelo
El modelo hace un eficiente trabajo al predecir si un usuario hizo clic en un anuncio, esto se puede observar
según el resultado obtenido de la función f1_score() con un 96%. Sin embargo, ¿cómo llegó a dicho
nivel de rendimiento para realizar predicciones?, ¿Cuánto contribuyó cada característica en la diferencia
entre la predicción final y la predicción promedio?.
Para responder a dichas preguntas es necesario encontrar los valores Shapley para cada característica, estos valores permiten determinar su contribución. Los pasos para obtener la importancia de la característica, se detallan a continuación:
- Obtener todos los subconjuntos que no contienen la función índice,
- Encontrar la contribución marginal de la característica para cada uno de estos subconjuntos,
- Sumar todas las contribuciones marginales para calcular las contribuciones de la característica.
El proceso para encontrar los valores de Shapley haciendo uso de la función shap(), se inserta el
modelo entrenado en la función, como se muestra a continuación.
explainer = shap.Explainer(model)
shap_values = explainer(X_frame)
Gráfico de Cascada
En este gráfico se visualizará la explicación de la primera predicción.
shap.plots.waterfall(shap_values[0])
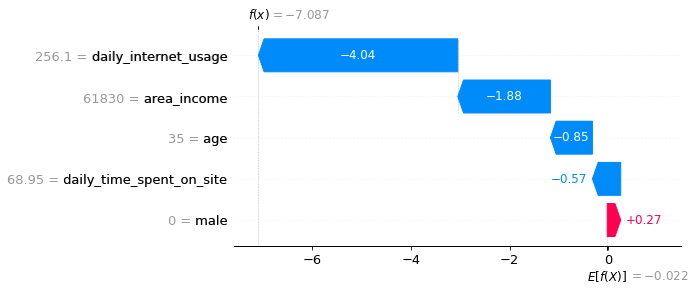
A través del gráfico anterior se puede saber la contribución de cada característica para la primera predicción de la siguiente manera:
- La barra azul muestra cuánto disminuye una característica en particular el valor de la predicción.
- La barra roja muestra cuánto aumenta una característica particular el valor de la predicción.
- Los valores negativos implican probabilidades inferiores a 0,5 de que la persona haya hecho clic en el anuncio.
Para cada uno de estos subconjuntos, la función shap() no elimina una característica para luego
volver a entrenar el modelo, sino que reemplaza esa característica con el valor promedio de esa característica
y luego genera las predicciones. Se debe esperar que la contribución total sea igual a la diferencia entre la
predicción y la predicción promedio.
A continuación, la visualización de la segunda predicción.
shap.plots.waterfall(shap_values[1])
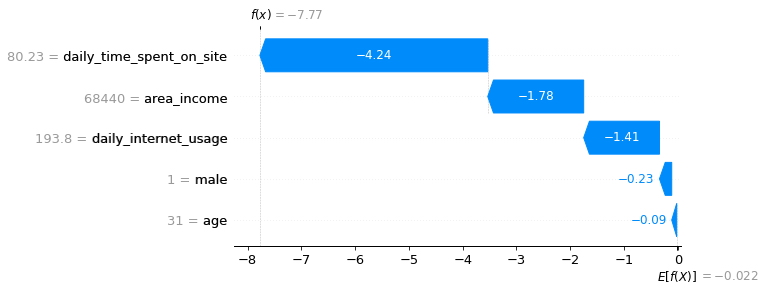
- De esta manera se puede observar la contribución de cada característica para la segunda predicción.
Gráfico Resumen
En lugar de observar visualizaciones para cada una de las instancias individualmente, se puede visualizar el impacto de manera general con varias instancias simultáneamente, haciendo uso del gráfico de resumen.
shap.summary_plot(shap_values, X)
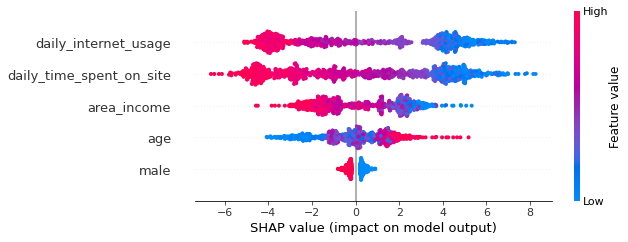
A través de la gráfica de resumen se pueden observar las características más importantes y su rango de efectos sobre el conjunto de datos. Del gráfico anterior se puede observar lo siguiente:
- El uso diario de Internet de un usuario, tiene el efecto más fuerte sobre si ese usuario hizo clic en un anuncio.
- A medida que aumenta el uso diario de Internet, es menos probable que un usuario haga clic en un anuncio.
- A medida que aumenta el tiempo diario que pasa un usuario en el sitio, es menos probable que haga clic en un anuncio.
- A medida que aumentan los ingresos del área, es menos probable que un usuario haga clic en un anuncio.
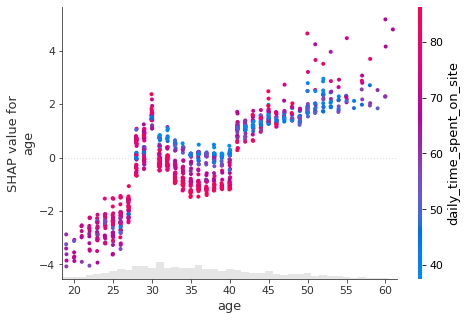
- A medida que aumenta la edad, es más probable que un usuario haga clic en un anuncio.
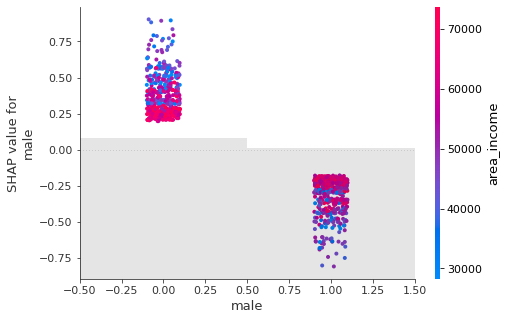
- Si un usuario es hombre, es menos probable que ese usuario haga clic en un anuncio.
Gráfico de Barras
A través del gráfico de barras de la función shap() se puede obtener la importancia de
características globales.
shap.plots.bar(shap_values)
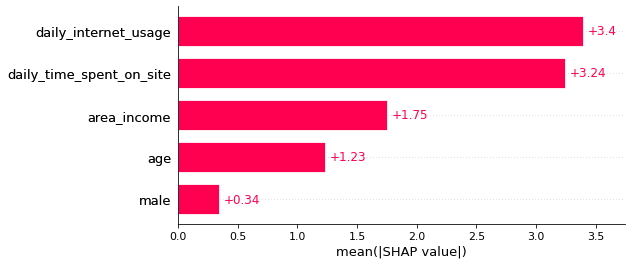
Gráfico de Dispersión de Dependencia
También se puede observar el efecto de una sola característica en todas las predicciones hechas por el modelo, utilizando el gráfico de dispersión de dependencia.
- Análisis para Uso diario de Internet.
shap.plots.scatter(shap_values[:, "daily_internet_usage"])
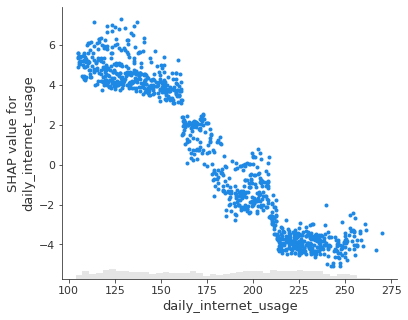
-
Se puede observar en el gráfico anterior, a medida que aumenta el uso diario de Internet, el valor de aditivos para el uso diario de Internet disminuye. Esto confirma lo observado en el gráfico anterior.
-
Se puede observar también la interacción entre la función de uso diario de Internet con otras funciones en el mismo gráfico al agregar
color = shap_valuesque observaremos a continuación. El diagrama de dispersión intentará seleccionar la columna de funciones con la interacción más fuerte en el uso diario de Internet, que es el tiempo diario que se pasa un usuario en el sitio.
shap.plots.scatter(shap_values[:, "daily_internet_usage"],
color = shap_values)
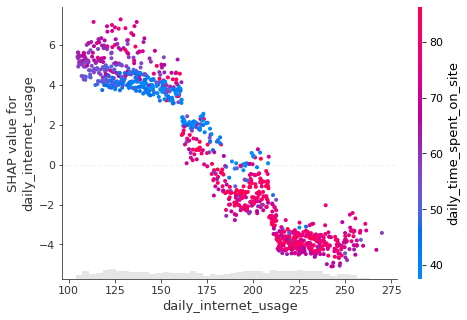
- Se puede observar, una persona que usa Internet durante 150 minutos por día y pasa una pequeña cantidad de tiempo en el sitio web por día tiene más probabilidades de hacer clic en el anuncio.
Se procederá a observar los gráficos de dispersión de otras características para confirmar los resultados del análisis del gráfico resumen.
- Tiempo diario en el sitio.
shap.plots.scatter(shap_values[:, "daily_time_spent_on_site"],
color = shap_values)
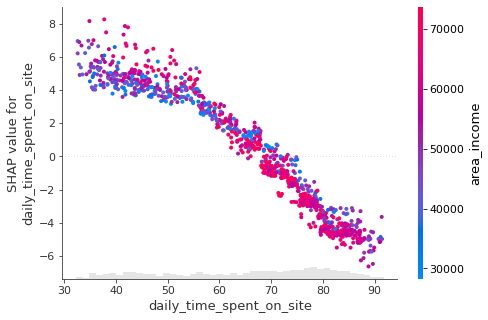
- Ingresos del área
shap.plots.scatter(shap_values[:, "area_income"],
color = shap_values)
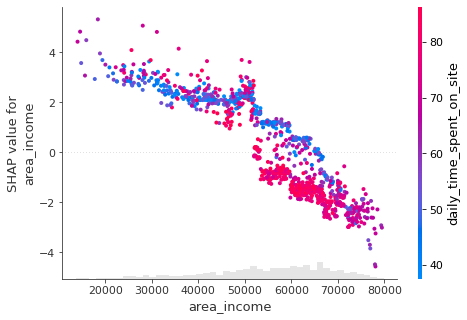
- Edad
shap.plots.scatter(shap_values[:, "age"],
color = shap_values)
- Género
shap.plots.scatter(shap_values[:, "male"],
color = shap_values)
Gráfica de Interacción
Se puede realizar un análisis a través de una matriz de interacciones entre entidades con el diagrama de resumen de valores de interacción. En este gráfico, los efectos principales están en la diagonal y los efectos de interacción están fuera de la diagonal.
# Para obtener los valores de interacción
shap_interaction_values = explainer.shap_interaction_values(X)
# Para resumir los valores de interacción
shap.summary_plot(shap_interaction_values, X_frame)
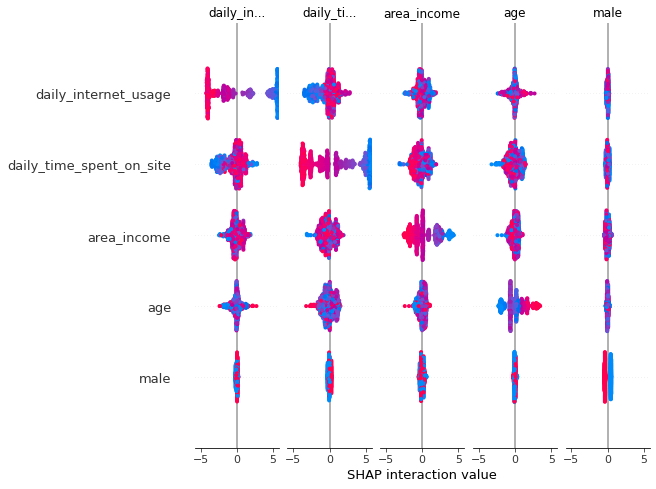
-
A través de la matriz se puede observar gráficamente la interacción entre características que confirman los análisis de los gráficos de características individuales y el gráfico resumen de características.
-
Es de esta manera, cómo a través de esta función
shap()se pueden obtener detalladamente los conocimientos esenciales para la interpretación del uso de las características en un modelo de aprendizaje automático.