Regresión Lineal Univariante.
Publicado el: 12 de Enero del 2021 - Jhonatan Montilla
La regresión lineal univariada se basa en determinar la relación entre una variable independiente (variable explicativa) y una variable dependiente. Para demostrarlo realizaremos un ejemplo donde el modelo realizará predicciones en la puntuación de un estudiante de un examen, en función de cuánto tiempo estuvo estudiando para tomar el examen. Optimizaremos los parámetros del modelo utilizando el método de descenso de gradiente y calcularemos la pérdida con el Error Cuadrático Medio (SME).
Podrá descargar el conjunto de datos directamente desde nuestro repositorio.
Primero se importan todas las librerías de Python necesarias y se carga el conjunto de datos.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
df = pd.read_csv('student_scores.csv')
df.head()
| Hours | Scores | |
|---|---|---|
| 0 | 2.5 | 21 |
| 1 | 5.1 | 47 |
| 2 | 3.2 | 27 |
| 3 | 8.5 | 75 |
| 4 | 3.5 | 30 |
-
Como puede observar, el conjunto de datos contiene dos columnas con las horas y las puntuaciones, la variable "Scores" será la variable objetivo. Se requeire predecir las puntuaciones en función de las horas de estudio.
-
Primeramente se almacenan las características y la variable objetivo en x, y respectivamente.
X = df['Hours'].values
y = df['Scores'].values
- La parte más importante del análisis de datos es, analizar los datos y visualizarlos. Veamos cómo se ven los datos gráficamente.
plt.scatter(X,y)
plt.show()
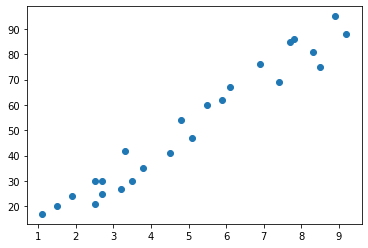
-
La regresión lineal univariada predice sobre la ecuación de una línea recta, es decir, y = mx + b
-
A partir de esta ecuación, se tiene X y se requiere calcular Y, sin embargo, no está disponible m y b, es decir, el gradiente o pendiente, así como tampoco la intersección de los ejes o coeficiente. Estos se conocen como parámetros del modelo ML.
-
Se puede calcular m y b con el método del descenso del gradiente (Gradient Descent). El descenso de gradiente es un algoritmo de optimización que se utiliza para minimizar la función de costo moviéndose iterativamente en la dirección del descenso más pronunciado según lo definido por el negativo del gradiente.
-
En el aprendizaje automático, se utiliza el descenso de gradientes para actualizar los parámetros de un modelo. Los parámetros se refieren a coeficientes en regresión lineal y pesos en redes neuronales.
-
El gradiente se puede calcular de la siguiente manera:
# Calcula m, b a través de Gradient Descent
def gradient(x, y):
m = b = 0 # Coeficiente e intercepción
iter = 1000
n = len(x)
lr = 0.01 # Tasa de aprendizaje
for i in range(iter):
y_pred = m * x + b
dm = -(2/n)*sum(x*(y-y_pred))
db = -(2/n)*sum(y-y_pred)
m = m - lr*dm
b = b - lr*db
return m,b
gradient(X,y)
(9.778905988234964, 2.4644522714760995)
-
Este método resta una pequeña porción de m y b de m y b en sí, es decir, derivadas de m (dm) y b (db). Por lo tanto, cada vez que se reste una pequeña posición de los parámetros, estos parámetros se encuentran en la pendiente más pronunciada.
-
El tamaño de estos pasos se denomina tasa de aprendizaje (lr). Podría ser 0.1, 0.01, 0.001..etc depende del problema a resolver y no de las iteraciones que se tienen que hacer.
-
Con una alta tasa de aprendizaje el modelo puede cubrir más terreno en cada paso, sin embargo, se corre el riesgo de sobrepasar el punto más bajo ya que la pendiente cambia constantemente. Con una tasa de aprendizaje muy baja, el modelo se puede mover con confianza en la dirección del gradiente negativo, debiso a que se recalcula con mucha frecuencia. Una tasa de aprendizaje baja es más precisa, pero calcular el gradiente requiere de mucho tiempo, por lo que es posible gastar mucho tiempo llegar al fondo.
Ahora se tienen calculadas m y b, se guardarán de la manera siguiente.
m, c = gradient(X,y)
- Procedemos a predecir con el modelo
# y = mx + c
pred = m * X + c
pred
array([26.91171724, 52.33687281, 33.75695143, 85.58515317, 36.69062323,
17.13281125, 92.43038736, 56.24843521, 83.62937197, 28.86749844,
77.76202838, 60.1599976 , 46.46952922, 34.73484203, 13.22124886,
89.49671557, 26.91171724, 21.04437365, 62.1157788 , 74.82835658,
28.86749844, 49.40320102, 39.62429503, 69.93890359, 78.73991898])
-
Lo que se obtiene es la predicción de puntuación sobre la base de las características o entradas suministradas (horas de estudio).
-
Las funciones de pérdida indican "qué tan bueno" es el modelo para hacer predicciones para un conjunto de parámetros dado.
-
La función de costo tiene su propia curva y sus propios gradientes. La pendiente de esta curva indica cómo actualizar los parámetros para hacer que el modelo sea más preciso.
-
El método más común para calcular la pérdida es el Error Cuadrático Medio (SME).
-
La librería de python Scikit-Learn tiene una función incorporada para calcular el SME, la cual veremos a continuación.
mean_squared_error(y, pred)
28.882802906830015
Conclusiones.¶
El resultado del SME es de aproximadamente 29%, según este resultado se podría concluir que el modelo actual es un modelo de gama media para predecir valores con el conjunto de datos dado. Cuanto menor sea la pérdida, más preciso será un modelo.
La pérdida de este modelo es significativamente baja. Sin embargo, existen otros modelos de regresión y aprendizaje automático con pérdidas mucho menores a este modelo, estos serían modelos de gama alta y tienen un nivel muy alto de confiabilidad.