10 de Abril del 2022 | Jhonatan Montilla
Tener una buena idea de un nuevo conjunto de datos no siempre es fácil y lleva tiempo. Sin embargo, un buen y amplio análisis exploratorio de datos (EDA) puede ayudar mucho a comprender su conjunto de datos, tener una idea de cómo están conectadas las cosas y qué se debe hacer para procesar adecuadamente su conjunto de datos.
En este artículo, abordaremos múltiples rutinas EDA útiles. Sin embargo, para mantener las cosas breves y compactas, es posible que no siempre profundicemos o expliquemos todas las implicaciones. Pero, en realidad, dedicar suficiente tiempo a un EDA adecuado para comprender completamente su conjunto de datos es una parte clave de cualquier buen proyecto de ciencia de datos. Como regla general, probablemente dedicará el 80 % de su tiempo a la preparación y exploración de datos y solo el 20 % al modelado real de aprendizaje automático.
Habiendo dicho todo esto, ¡vamos a sumergirnos en ello!.
En general, el enfoque EDA es muy iterativo. Al final de su investigación, puede descubrir algo que requerirá que rehaga todo una vez más. ¡Eso es normal! Pero para imponer al menos un poco de estructura, propongo la siguiente estructura para sus investigaciones:
Pero primero necesitamos encontrar un conjunto de datos interesante. Avancemos y carguemos el conjunto de datos de seguridad vial de OpenML .
from sklearn.datasets import fetch_openml
import pandas as pd
import matplotlib.pyplot as plt
import missingno as msno
import seaborn as sns
import numpy as np
# Descargar el conjunto de datos de openml
dataset = fetch_openml(data_id = 42803,
as_frame = True)
# Extraiga la matriz de características X y muestre 5 muestras aleatorias
df_X = dataset["frame"]
df_X.sample(5)
| Accident_Index | Vehicle_Reference_df_res | Vehicle_Type | Towing_and_Articulation | Vehicle_Manoeuvre | Vehicle_Location-Restricted_Lane | Junction_Location | Skidding_and_Overturning | Hit_Object_in_Carriageway | Vehicle_Leaving_Carriageway | ... | Age_Band_of_Casualty | Casualty_Severity | Pedestrian_Location | Pedestrian_Movement | Car_Passenger | Bus_or_Coach_Passenger | Pedestrian_Road_Maintenance_Worker | Casualty_Type | Casualty_Home_Area_Type | Casualty_IMD_Decile | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 154113 | 201520T049545 | 1.0 | 9.0 | 0.0 | 18.0 | 0.0 | 1.0 | 2.0 | 10.0 | 2.0 | ... | 5.0 | 1.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 9.0 | 1.0 | 5.0 |
| 312648 | 2015521501818 | 1.0 | 9.0 | 0.0 | 18.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 6.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 9.0 | 1.0 | 10.0 |
| 228653 | 2015420033765 | 5.0 | 9.0 | 0.0 | 18.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 4.0 | 3.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 9.0 | NaN | NaN |
| 233448 | 201542I164505 | 1.0 | 9.0 | 0.0 | 9.0 | 0.0 | 7.0 | 0.0 | 0.0 | 0.0 | ... | 6.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 5.0 | 1.0 | 6.0 |
| 189611 | 2015320020402 | 2.0 | 9.0 | 0.0 | 18.0 | 0.0 | 8.0 | 0.0 | 0.0 | 0.0 | ... | 9.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 9.0 | 2.0 | 4.0 |
5 rows × 67 columns
Antes de ver el contenido de nuestra matriz de características $X$, veamos primero la estructura general del conjunto de datos. Por ejemplo, ¿cuántas columnas y filas tiene el conjunto de datos?.
# Mostrar el tamaño del conjunto de datos
df_X.shape
(363243, 67)
Entonces sabemos que este conjunto de datos tiene 363.243 muestras y 67 características. ¿Y cuántos tipos de datos diferentes contienen estas 67 características?
# Cuente cuántas veces está presente cada tipo de datos en el conjunto de datos
pd.value_counts(df_X.dtypes)
float64 61 object 6 dtype: int64
Los tipos de datos pueden ser numéricos y no numéricos. Primero, echemos un vistazo más de cerca a las entradas no numéricas.
# Mostrar características no numéricas
df_X.select_dtypes(exclude = "number").head()
| Accident_Index | Sex_of_Driver | Date | Time | Local_Authority_(Highway) | LSOA_of_Accident_Location | |
|---|---|---|---|---|---|---|
| 0 | 201501BS70001 | 1.0 | 12/01/2015 | 18:45 | E09000020 | E01002825 |
| 1 | 201501BS70002 | 1.0 | 12/01/2015 | 07:50 | E09000020 | E01002820 |
| 2 | 201501BS70004 | 1.0 | 12/01/2015 | 18:08 | E09000020 | E01002833 |
| 3 | 201501BS70005 | 1.0 | 13/01/2015 | 07:40 | E09000020 | E01002874 |
| 4 | 201501BS70008 | 1.0 | 09/01/2015 | 07:30 | E09000020 | E01002814 |
Aunque Sex_of_Driver es una característica numérica, de alguna manera se almacenó como no numérica. Esto a veces se debe a algún error tipográfico en la grabación de datos. Así que cuidémonos de eso:
# Cambia el tipo de datos de 'Sex_of_Driver'
df_X["Sex_of_Driver"] = df_X["Sex_of_Driver"].astype("float")
Usando la función .describe() también podemos investigar cuántos valores únicos tiene cada característica no numérica y con qué frecuencia está presente el valor más destacado.
df_X.describe(exclude = "number")
| Accident_Index | Date | Time | Local_Authority_(Highway) | LSOA_of_Accident_Location | |
|---|---|---|---|---|---|
| count | 363243 | 319866 | 319822 | 319866 | 298758 |
| unique | 140056 | 365 | 1439 | 204 | 25979 |
| top | 201543P296025 | 14/02/2015 | 17:30 | E10000017 | E01028497 |
| freq | 1332 | 2144 | 2972 | 8457 | 1456 |
A continuación, echemos un vistazo más de cerca a las características numéricas. Más precisamente, investiguemos cuántos valores únicos tiene cada una de estas características. Este proceso nos dará información sobre la cantidad de características binarias (2 valores únicos), ordinales (de 3 a ~10 valores únicos) y continuas (más de 10 valores únicos) en el conjunto de datos
# Para cada característica numérica, calcule el número de entradas únicas
unique_values = df_X.select_dtypes(include = "number").nunique().sort_values()
# Trazar información con el eje y en escala logarítmica
unique_values.plot.bar(logy = True,
figsize = (15, 4),
title = "Valores únicos por característica");
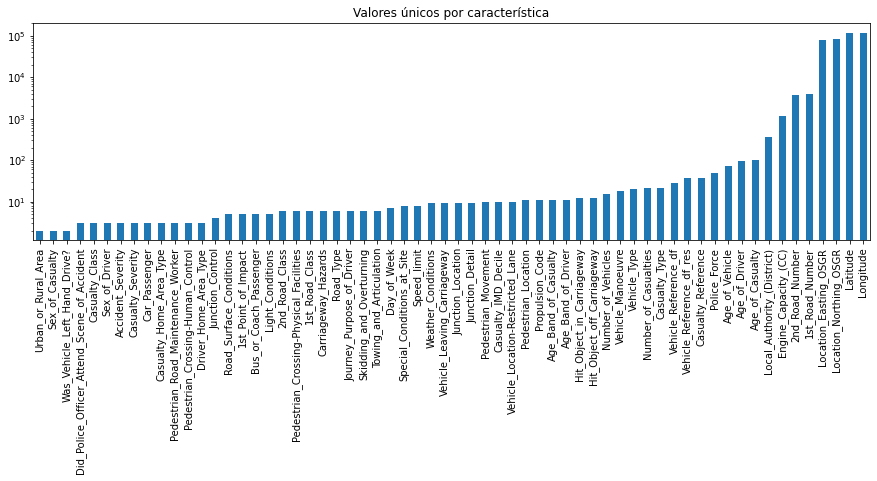
Al final de esta primera investigación, deberíamos tener una mejor comprensión de la estructura general de nuestro conjunto de datos. Número de muestras y funciones, qué tipo de datos tiene cada función y cuántos de ellos son binarios, ordinales, categóricos o continuos. Para obtener una forma alternativa de obtener este tipo de información, también puede usar df_X.info() o df_X.describe().
Antes de centrarnos en el contenido real almacenado en estas funciones, primero echemos un vistazo a la calidad general del conjunto de datos. El objetivo es tener una vista global del conjunto de datos con respecto a cosas como duplicados, valores faltantes y entradas no deseadas o errores de registro.
Los duplicados son entradas que representan el mismo punto de muestra varias veces. Por ejemplo, si una medición fue registrada dos veces por dos personas diferentes. Detectar tales duplicados no siempre es fácil, ya que cada conjunto de datos puede tener un identificador único (por ejemplo, un número de índice o un tiempo de registro que es único para cada nueva muestra) que quizás desee ignorar primero.
# Verifique el número de duplicados mientras ignora la función de índice
n_duplicates = df_X.drop(labels = ["Accident_Index"],
axis = 1).duplicated().sum()
print(f"pareces tener {n_duplicates} duplicados en su base de datos.")
pareces tener 22 duplicados en su base de datos.
Para manejar estos duplicados, simplemente puede eliminarlos con .drop_duplicates().
# Extraiga los nombres de columna de todas las funciones, excepto 'Accident_Index'
columns_to_consider = df_X.drop(labels = ["Accident_Index"],
axis = 1).columns
# Eliminar duplicados en función de 'columns_to_consider'
df_X = df_X.drop_duplicates(subset = columns_to_consider)
df_X.shape
(363221, 67)
Otro problema de calidad que vale la pena investigar son los valores faltantes. Tener algunos valores faltantes es normal. Lo que queremos identificar en esta etapa son grandes agujeros en el conjunto de datos, es decir, muestras o características con muchos valores faltantes.
Para ver el número de valores faltantes por muestra, tenemos múltiples opciones. La más directa es simplemente visualizar la salida de df_X.isna(), con algo como esto:
plt.figure(figsize = (10, 8))
plt.imshow(df_X.isna(),
aspect = "auto",
interpolation = "nearest",
cmap = "gray")
plt.xlabel("Número de columna")
plt.ylabel("Numero de muestra");
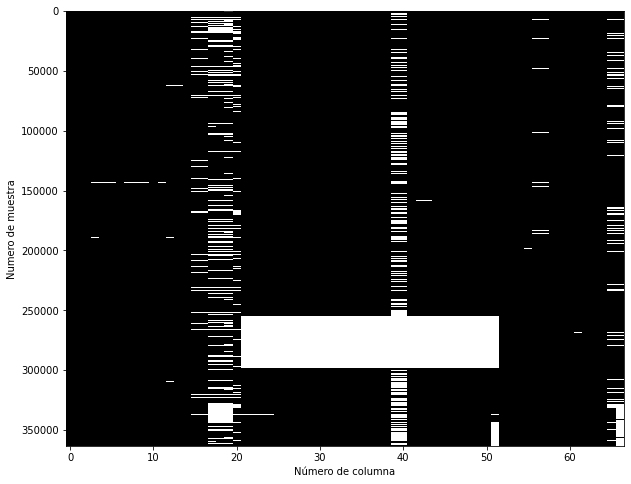
Esta figura muestra en el eje Y cada una de las 360.000 muestras individuales, y en el eje X si alguna de las 67 características contiene un valor faltante. Si bien esta ya es una trama útil, un enfoque aún mejor es usar la biblioteca missingno para obtener una trama como esta:
msno.matrix(df_X,
labels = True,
sort = "descending");

A partir de estos dos gráficos, podemos ver que el conjunto de datos tiene un todo enorme, causado por algunas muestras en las que faltan más del 50% de los valores de las características. Para esas muestras, probablemente no sea una buena idea llenar los valores que faltan con algunos valores de reemplazo.
Por lo tanto, sigamos adelante y eliminemos muestras que tengan más del 20% de valores faltantes. El umbral está inspirado en la información de la columna "Integridad de los datos" a la derecha de esta figura.
df_X = df_X.dropna(thresh = df_X.shape[1] * 0.80,
axis = 0).reset_index(drop = True)
df_X.shape
(319790, 67)
Como siguiente paso, veamos ahora la cantidad de valores faltantes por función. Para esto, podemos usar algunos trucos de pandas para identificar rápidamente la proporción de valores faltantes por característica.
df_X.isna().mean().sort_values().plot(
kind = "bar", figsize = (15, 4),
title = "Porcentaje de valores faltantes por característica",
ylabel = "Proporción de valores perdidos por característica");
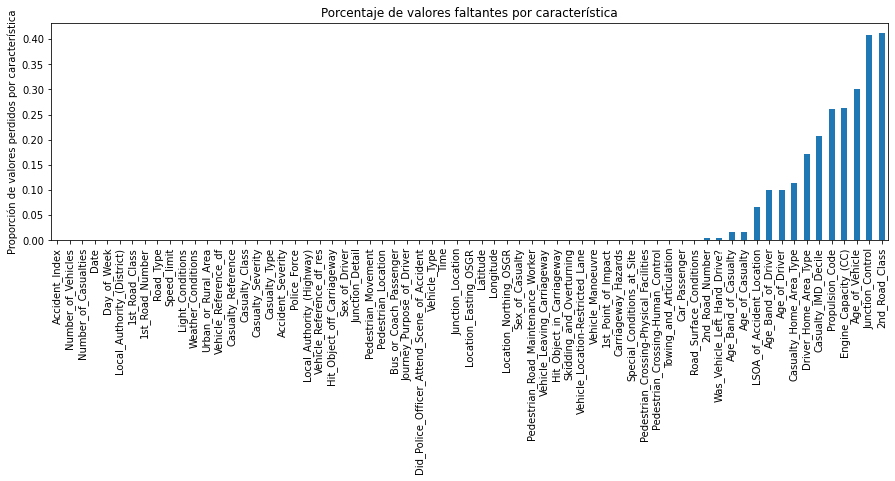
De esta figura podemos ver que la mayoría de las características no contienen valores faltantes. No obstante, características como 2nd_Road_Class, Junction_Control, Age_of_Vehicletodavía contienen muchos valores faltantes. Así que sigamos adelante y eliminemos cualquier función con más del
15% de valores faltantes.
df_X = df_X.dropna(thresh = df_X.shape[0] * 0.85,
axis = 1)
df_X.shape
(319790, 60)
Valores faltantes: no existe un orden estricto para eliminar los valores faltantes. Para algunos conjuntos de datos, abordar primero las características y luego las muestras podrían ser mejores. Además, el umbral en el que decidas para descartar valores faltantes por función o cambios de muestra de un conjunto de datos a otro, y depende de lo que pretende hacer con el conjunto de datos más adelante.
Además, hasta ahora solo abordamos los grandes agujeros en el conjunto de datos, aún no sabemos cómo llenar los vacíos más pequeños. Este es contenido para otro post.
Otra fuente de problemas de calidad en un conjunto de datos puede deberse a entradas no deseadas o errores de registro. Es importante distinguir tales muestras de simples valores atípicos. Si bien los valores atípicos son puntos de datos que son inusuales para una determinada distribución de características, las entradas no deseadas o los errores de registro son muestras que no deberían estar allí en primer lugar.
Por ejemplo, un registro de temperatura de 45 °C en Suiza podría ser un valor atípico (como "muy inusual"), mientras que un registro de 90 °C sería un error. De manera similar, un registro de temperatura desde la cima del Mont Blanc podría ser físicamente posible, pero lo más probable es que no se incluya en un conjunto de datos sobre ciudades suizas.
Por supuesto, detectar dichos errores y entradas no deseadas y distinguirlos de los valores atípicos no siempre es sencillo y depende en gran medida del conjunto de datos. Un enfoque para esto es tomar una vista global del conjunto de datos y ver si puede identificar algunos patrones muy inusuales.
Para trazar esta vista global del conjunto de datos, al menos para las características numéricas, puede usar la función .plot() de pandas y combinarla con los siguientes parámetros:
lw=0: lw representa el ancho de línea. 0 significa que no queremos mostrar ninguna línea
marker=".": En lugar de líneas, le decimos a la gráfica que use . como marcadores para cada punto de datos
subplots=True: subplots le dice a pandas que trace cada característica en una subtrama separada
layout=(-1, 4): este parámetro le dice a pandas cuántas filas y columnas usar para las subparcelas. -1 significa "tantas como sea necesario", mientras que 2 significa usar 2 columnas por fila.
figsize=(15, 30), markersize=1: para asegurarse de que la figura sea lo suficientemente grande, recomendamos tener una altura de figura de aproximadamente el número de características y ajustar el markersize en consecuencia.
Entonces, ¿cómo es esta trama?.
df_X.plot(lw = 0,
marker = ".",
subplots = True,
layout = (-1, 4),
figsize = (15, 30),
markersize = 1);
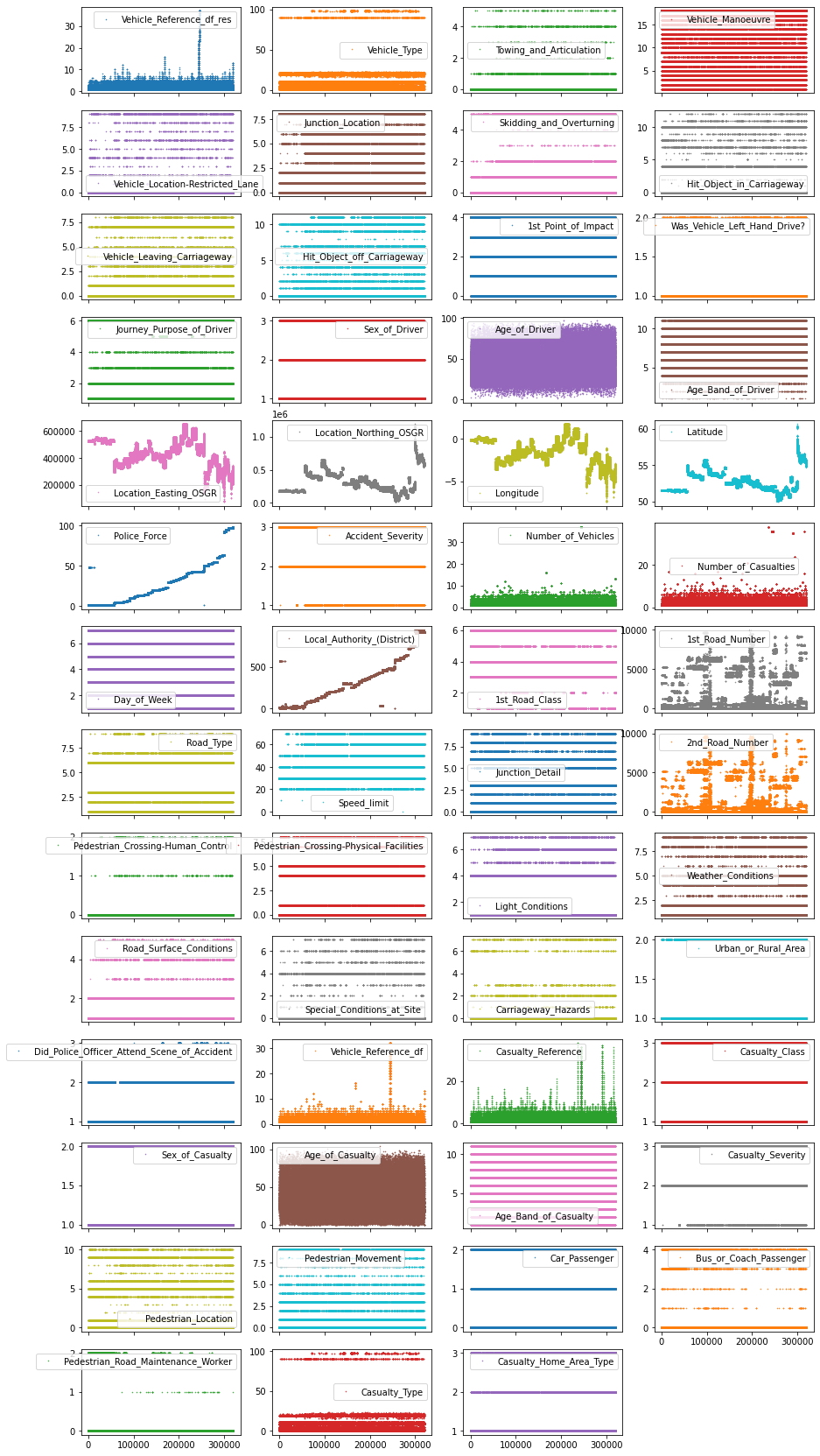
Cada punto en esta figura es una muestra (es decir, una fila) en nuestro conjunto de datos y cada subparcela representa una característica diferente. El eje y muestra el valor de la característica, mientras que el eje x es el índice de la muestra. Este tipo de gráficos pueden brindarle muchas ideas para la limpieza de datos y EDA. Por lo general, tiene sentido invertir tanto tiempo como sea necesario hasta que esté satisfecho con el resultado de esta visualización.
Identificar entradas no deseadas o errores de registro en características no numéricas es un poco más complicado. Dado que en este punto, solo queremos investigar la calidad general del conjunto de datos. Entonces, lo que podemos hacer es echar un vistazo general a cuántos valores únicos contiene cada una de estas características no numéricas y con qué frecuencia se representa su categoría más frecuente.
# Extraer propiedades descriptivas de características no numéricas
df_X.describe(exclude = ["number",
"datetime"])
| Accident_Index | Date | Time | Local_Authority_(Highway) | LSOA_of_Accident_Location | |
|---|---|---|---|---|---|
| count | 319790 | 319790 | 319746 | 319790 | 298693 |
| unique | 123645 | 365 | 1439 | 204 | 25977 |
| top | 201543P296025 | 14/02/2015 | 17:30 | E10000017 | E01028497 |
| freq | 1332 | 2144 | 2969 | 8457 | 1456 |
Hay varias formas de optimizar la investigación de calidad para cada característica no numérica individual. Ninguno de ellos es perfecto, y todos requerirán alguna investigación de seguimiento. Pero con el fin de mostrar una solución de este tipo, lo que podríamos hacer es recorrer todas las características no numéricas y trazar para cada una de ellas el número de ocurrencias por valor único.
# Crear objeto de figura con 3 subparcelas
fig, axes = plt.subplots(ncols = 1,
nrows = 3,
figsize = (12, 8)
)
# Identificar características no numéricas
df_non_numerical = df_X.select_dtypes(exclude = ["number",
"datetime"]
)
# Recorra las funciones y coloque cada subtrama en un objeto de eje matplotlib
for col, ax in zip(df_non_numerical.columns, axes.ravel()):
# Selecciona una sola característica y cuenta el número de ocurrencias por valor único
df_non_numerical[col].value_counts().plot(
# Traza esta información en una figura con el eje Y a escala logarítmica
logy = True,
title = col,
lw = 0,
marker = ".",
ax = ax)
plt.tight_layout();
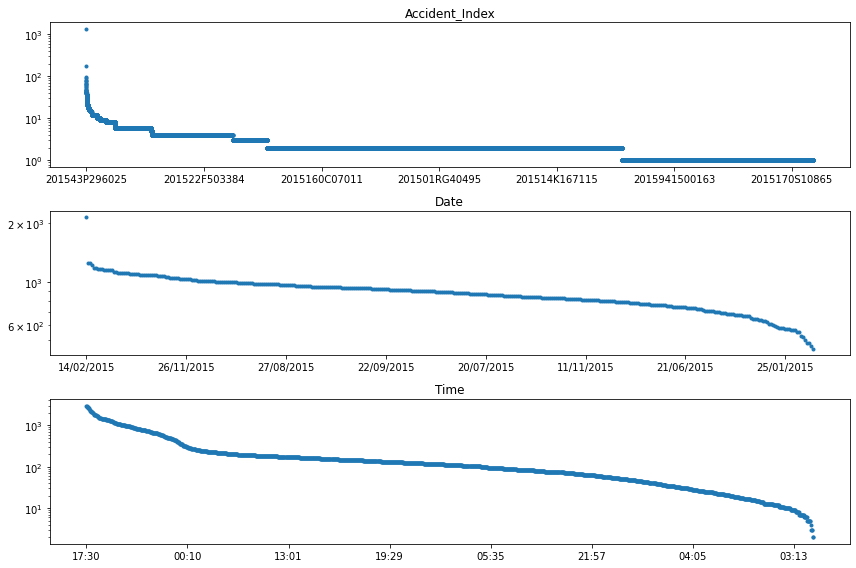
Podemos ver que el accidente más frecuente (es decir, Accident_Index), tuvo más de 100 personas involucradas. Profundizando un poco más (es decir, observando las características individuales de este accidente), pudimos identificar que este accidente ocurrió el 24 de febrero de 2015 a las 11:55 en Cardiff, Reino Unido. Una búsqueda rápida en Internet revela que esta entrada corresponde a un accidente afortunadamente no letal que incluye un minibús lleno de jubilados.
La decisión de qué se debe hacer con entradas tan únicas se deja una vez más en manos subjetivas de la persona que analiza el conjunto de datos. Sin ninguna buena justificación del POR QUÉ, y solo con la intención de mostrarle el CÓMO, avancemos y eliminemos los 10 accidentes más frecuentes de este conjunto de datos.
# Recopilar valores de entrada de los 10 accidentes más frecuentes
accident_ids = df_non_numerical["Accident_Index"].value_counts().head(10).index
# Elimina accidentes de la lista 'accident_ids'
df_X = df_X[~df_X["Accident_Index"].isin(accident_ids)]
df_X.shape
(317665, 60)
Al final de esta segunda investigación, deberíamos tener una mejor comprensión de la calidad general de nuestro conjunto de datos. Observamos duplicados, valores faltantes y entradas no deseadas o errores de registro. Es importante señalar que aún no discutimos cómo abordar los valores atípicos o faltantes restantes en el conjunto de datos. Esta es una tarea para la próxima investigación, pero no se tratará en este artículo.
Hasta ahora, solo analizamos la estructura general y la calidad del conjunto de datos. Vayamos ahora un paso más allá y echemos un vistazo al contenido real. En un escenario ideal, tal investigación se haría característica por característica. Pero esto se vuelve muy engorroso una vez que tiene más de 20-30 funciones.
Por esta razón (y para que este artículo sea lo más breve posible), exploraremos tres enfoques diferentes que pueden brindarle una descripción general muy rápida del contenido almacenado en cada función y cómo se relacionan.
Observar la distribución de valor de cada característica es una excelente manera de comprender mejor el contenido de sus datos. Además, puede ayudar a guiar su EDA y proporciona mucha información útil con respecto a la limpieza de datos y la transformación de características. La forma más rápida de hacer esto para las características numéricas es usando gráficas de histogramas. Afortunadamente, pandas viene con una función de histograma incorporada que permite trazar múltiples características a la vez.
# Traza el histograma para cada característica numérica en una subparcela separada
df_X.hist(bins = 25,
figsize = (15, 25),
layout = (-1, 5),
edgecolor ="black"
)
plt.tight_layout();
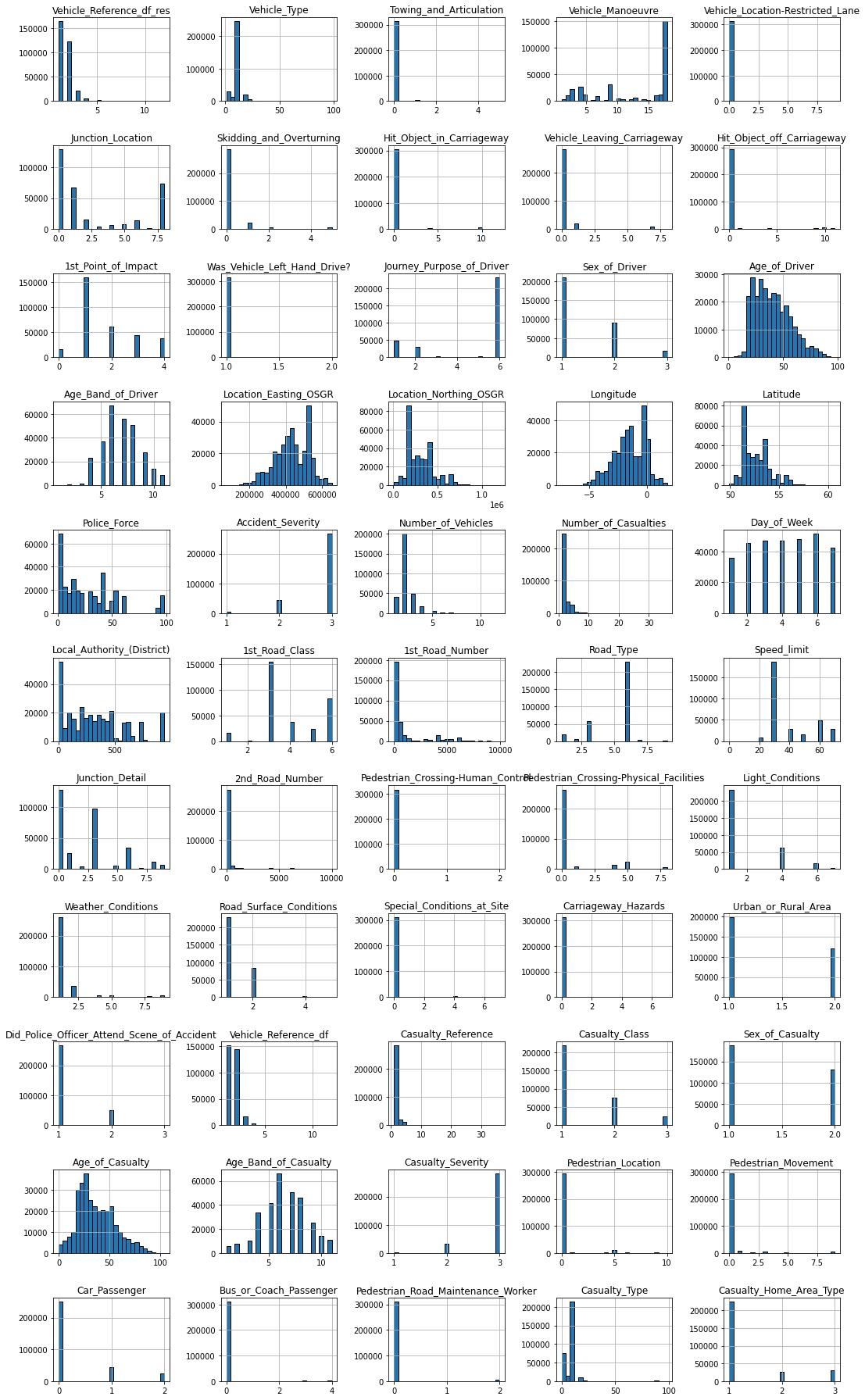
Hay muchas cosas muy interesantes visibles en esta trama. Por ejemplo...
Entrada más frecuente: algunas características, como Remolque_y_articulación o ¿Era_el_vehículo_conducción_a la izquierda? en su mayoría contienen entradas de una sola categoría. Usando la función .mode(), podríamos, por ejemplo, extraer la proporción de la entrada más frecuente para cada función y visualizar esa información.
# Recopila para cada característica la entrada más frecuente
most_frequent_entry = df_X.mode()
# Comprueba para cada entrada si contiene la entrada más frecuente
df_freq = df_X.eq(most_frequent_entry.values,
axis = 1
)
# Calcula la media de la ocurrencia 'is_most_frequent'
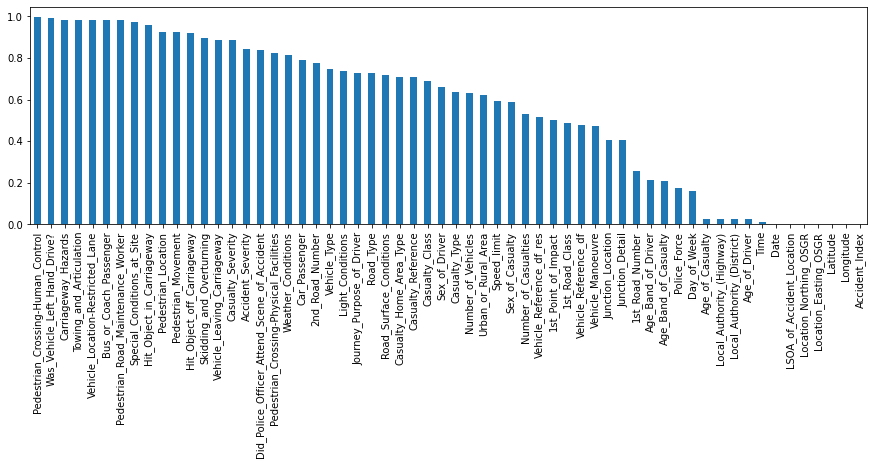
df_freq = df_freq.mean().sort_values(ascending = False)
# Muestre las 5 funciones principales con la proporción más alta de contenido de valor singular
display(df_freq.head())
# Visualiza la tabla 'df_freq'
df_freq.plot.bar(figsize = (15, 4));
Pedestrian_Crossing-Human_Control 0.995259 Was_Vehicle_Left_Hand_Drive? 0.990137 Carriageway_Hazards 0.983646 Towing_and_Articulation 0.983221 Vehicle_Location-Restricted_Lane 0.982088 dtype: float64
Distribuciones de valores sesgados: Ciertos tipos de características numéricas también pueden mostrar distribuciones fuertemente no gaussianas. En ese caso, es posible que desee pensar en cómo puede transformar estos valores para que tengan una distribución más normal. Por ejemplo, para datos sesgados a la derecha, podría usar una transformación de registro.
El siguiente paso en la lista es la investigación de patrones específicos de características. El objetivo de esta parte es doble:
Pero antes de sumergirnos en estas dos preguntas, echemos un vistazo más de cerca a algunas funciones 'seleccionadas al azar'.
df_X[["Location_Northing_OSGR",
"1st_Road_Number",
"Journey_Purpose_of_Driver",
"Pedestrian_Crossing-Physical_Facilities"]].plot(lw = 0,
marker = ".",
subplots = True,
layout = (-1, 2),
markersize = 0.1,
figsize = (15, 6));
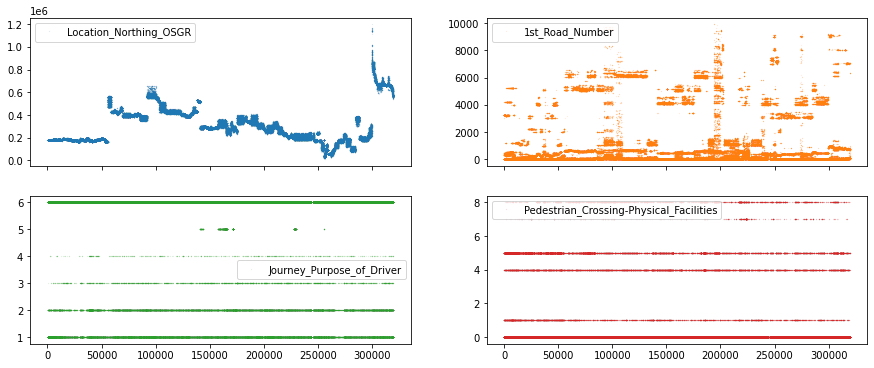
En la fila superior, podemos ver características con valores continuos (p. ej., aparentemente cualquier número de la recta numérica), mientras que en la fila inferior tenemos características con valores discretos (p. ej., 1, 2, 3 pero no 2,34).
Si bien hay muchas maneras de explorar nuestras características para patrones particulares, simplifiquemos nuestra opción al decidir que tratamos las características con menos de 25 características únicas como características discretas u ordinales, y las otras características como funciones continuas**.
# Crea una máscara para identificar características
# numéricas con más o menos de 25 características únicas
cols_continuous = df_X.select_dtypes(include = "number").nunique() >= 25
Ahora que tenemos una forma de seleccionar las características continuas, sigamos adelante y usemos el pairplot de seaborn para visualizar las relaciones entre estas características. Importante tener en cuenta, la rutina de tramas de pares de Seaborn puede tardar mucho tiempo en crear todas las tramas secundarias. Por lo tanto, recomendamos no usarlo para más de ~ 10 funciones a la vez.
# Cree un nuevo marco de datos que solo contenga las características continuas
df_continuous = df_X[cols_continuous[cols_continuous].index]
df_continuous.shape
(317665, 11)
Dado que en nuestro caso solo tenemos 11 características, podemos continuar con el diagrama de pares. De lo contrario, usar algo como df_continuous.iloc[:, :5] podría ayudar a reducir la cantidad de características para trazar.
sns.pairplot(df_continuous,
height = 1.5,
plot_kws = {"s": 2, "alpha": 0.2});
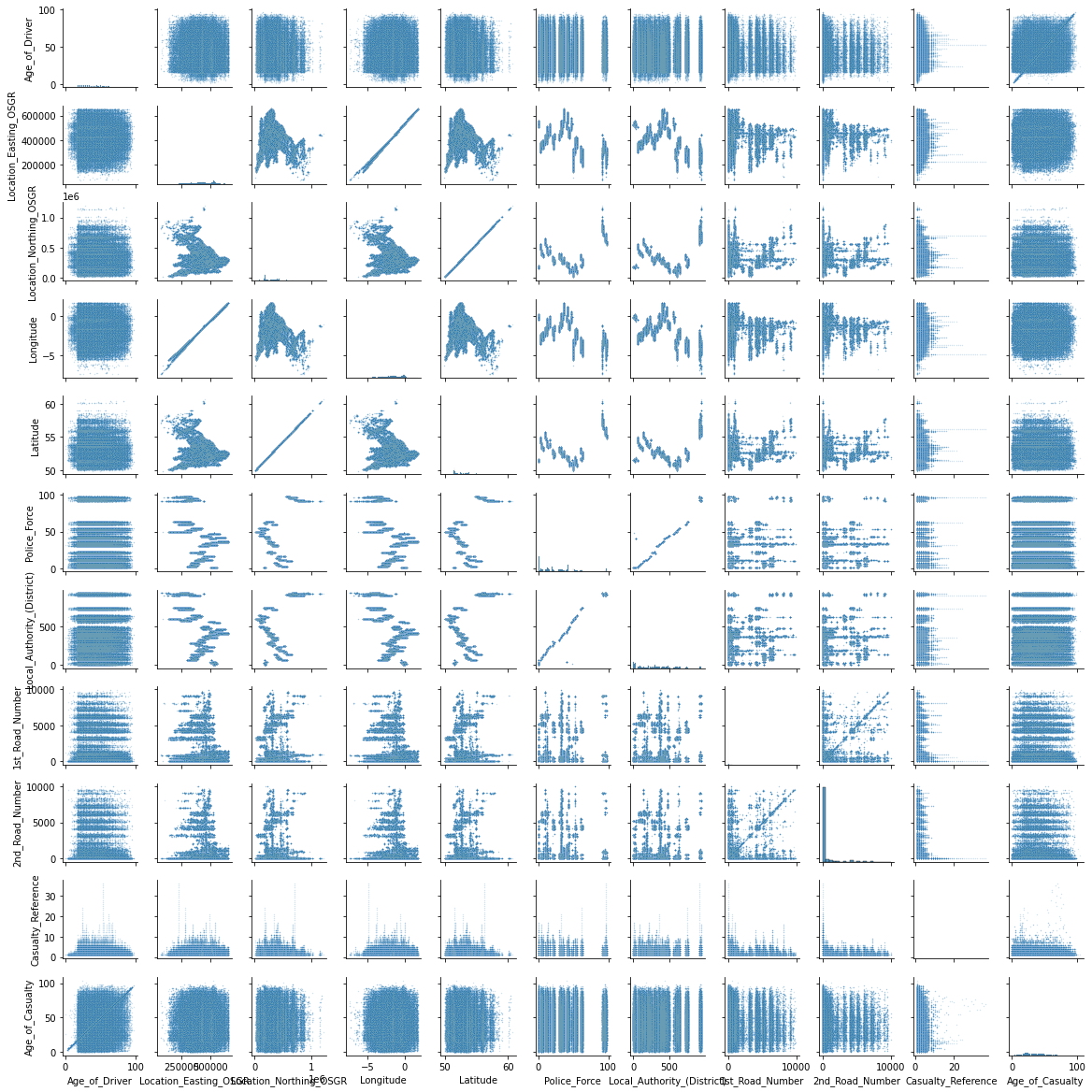
Parece haber una relación extraña entre algunas características en la esquina superior izquierda. Location_Easting_OSGR y Longitude, así como Location_Easting_OSGR y Latitude parecen tener una relación lineal muy fuerte.
sns.pairplot(
df_X, plot_kws = {"s": 3, "alpha": 0.2},
hue = "Police_Force",
palette = "Spectral",
x_vars = ["Location_Easting_OSGR", "Location_Northing_OSGR", "Longitude"],
y_vars = "Latitude"
);
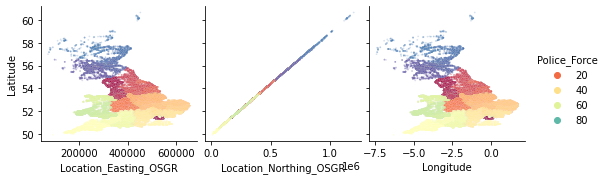
Sabiendo que estas características contienen información geográfica, una EDA más profunda con respecto a la geolocalización podría ser fructífera. Sin embargo, por ahora dejaremos la investigación adicional de esta gráfica de pares para el lector curioso y continuaremos con la exploración de las características discretas y ordinales.
Encontrar patrones en las características discretas u ordinales es un poco más complicado. Pero también aquí, algunos pandas rápidos y trucos marinos pueden ayudarnos a obtener una visión general de nuestro conjunto de datos. Primero, seleccionemos las columnas que queremos investigar.
# Cree un nuevo marco de datos que no contenga las características continuas numéricas
df_discrete = df_X[cols_continuous[~cols_continuous].index]
df_discrete.shape
(317665, 44)
Como siempre, hay varias formas de investigar todas estas características. Probemos un ejemplo, usando stripplot() de seaborn junto con un práctico bucle for zip() para subtramas.
Nota, para distribuir los valores en la dirección del eje y, debemos elegir una característica en particular (con suerte, informativa). Si bien la función 'correcta' puede ayudar a identificar algunos patrones interesantes, por lo general, cualquier función continua debería ser suficiente. El principal interés en este tipo de gráfico es ver cuántas muestras contiene cada valor discreto.
# Establecer el número de columnas y filas necesarias para trazar todas las características
n_cols = 5
n_elements = len(df_discrete.columns)
n_rows = np.ceil(n_elements / n_cols).astype("int")
# Especifique y_value para distribuir datos (idealmente, una característica continua)
y_value = df_X["Age_of_Driver"]
# Cree un objeto de figura con tantas filas y columnas como sea necesario
fig, axes = plt.subplots(ncols = n_cols,
nrows = n_rows,
figsize = (15, n_rows * 2.5))
# Recorra las funciones y coloque cada subtrama en un objeto de eje matplotlib
for col, ax in zip(df_discrete.columns, axes.ravel()):
sns.stripplot(data = df_X,
x = col,
y = y_value,
ax = ax,
palette = "tab10",
size = 1,
alpha = 0.5
)
plt.tight_layout();

Hay demasiadas cosas para comentar aquí, así que centrémonos en algunas. En particular, centrémonos en 6 características donde los valores aparecen en un patrón particular o donde algunas categorías parecen ser mucho menos frecuentes que otras. Y para agitar un poco las cosas, ahora usemos la función Longitud para estirar los valores sobre el eje y.
# Especifique las características de interés
selected_features = ["Vehicle_Reference_df_res",
"Towing_and_Articulation",
"Skidding_and_Overturning",
"Bus_or_Coach_Passenger",
"Pedestrian_Road_Maintenance_Worker",
"Age_Band_of_Driver"]
# Crea una figura con subtramas de 3 x 2
fig, axes = plt.subplots(ncols = 3,
nrows = 2,
figsize = (16, 8)
)
# Recorra estas características y grafique
# las entradas de cada característica contra `Latitude`
for col, ax in zip(selected_features, axes.ravel()):
sns.stripplot(data = df_X,
x = col,
y = df_X["Latitude"],
ax = ax,
palette = "tab10",
size = 2,
alpha = 0.5
)
plt.tight_layout();
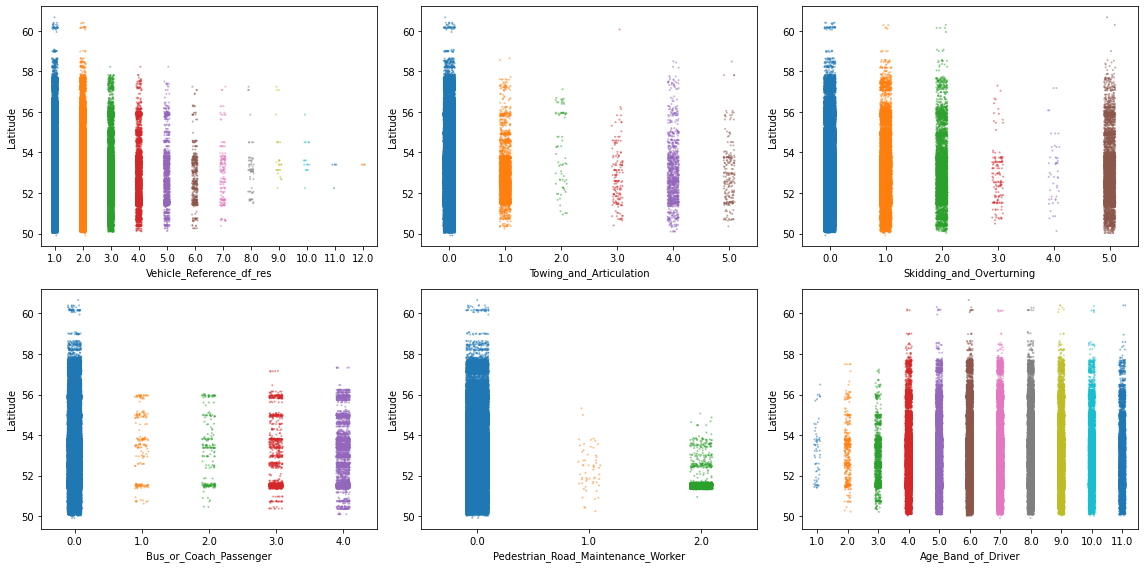
Este tipo de gráficos ya son muy informativos, pero ocultan regiones donde hay muchos puntos de datos a la vez. Por ejemplo, parece haber una alta densidad de puntos en algunas de las parcelas en la latitud 52. Así que echemos un vistazo más de cerca con un gráfico apropiado, como violineplot (o boxenplot o boxplot para el caso). Y para ir un paso más allá, separemos también cada visualización por Urban_or_Rural_Area.
# Crea una figura con subtramas de 3 x 2
fig, axes = plt.subplots(ncols = 3,
nrows = 2,
figsize = (16, 8)
)
# Recorra estas características y grafique las
# entradas de cada característica contra `Latitude`
for col, ax in zip(selected_features, axes.ravel()):
sns.violinplot(data = df_X,
x = col,
y = df_X["Latitude"],
palette = "Set2",
split = True,
hue = "Urban_or_Rural_Area",
ax = ax)
plt.tight_layout();
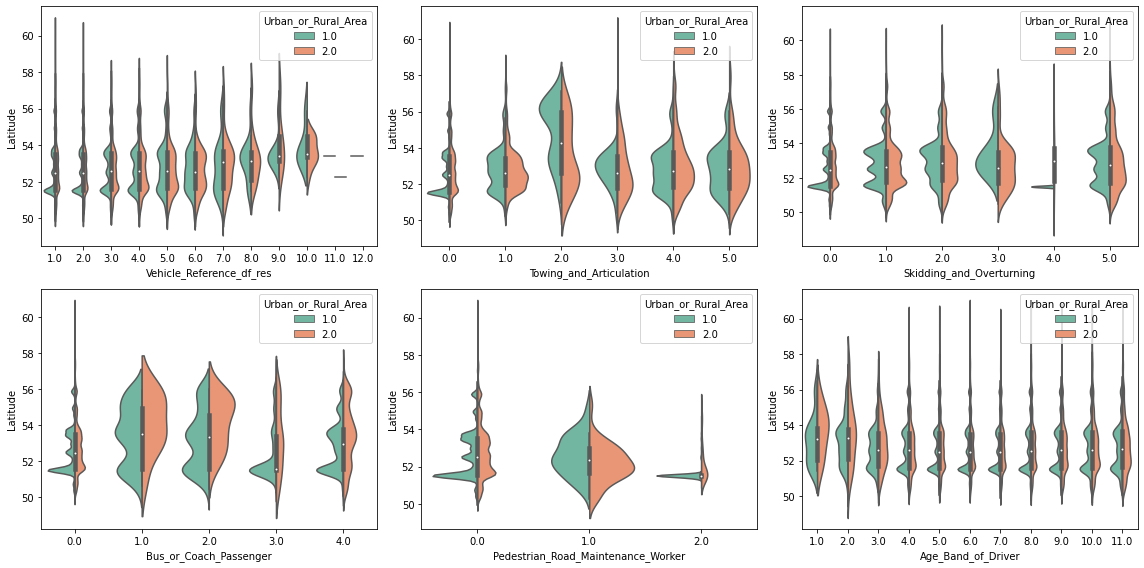
¡Interesante! Podemos ver que algunos valores en las características son más frecuentes en áreas urbanas que en áreas rurales (y viceversa). Además, como se sospecha, parece haber un pico de alta densidad en la latitud 51,5. Es muy probable que esto se deba a la región más densamente poblada alrededor de Londres (en 51.5074°).
Por último, pero no menos importante, echemos un vistazo a las relaciones entre las características. Más precisamente, cómo se correlacionan. La forma más rápida de hacerlo es mediante la función .corr() de pandas. Así que sigamos adelante y calculemos la matriz de correlación característica a característica para todas las características numéricas.
# Calcula la correlación de características
df_corr = df_X.corr(method = "pearson")
Nota: Según el conjunto de datos y el tipo de características (por ejemplo, características ordinales o continuas), es posible que desee utilizar el método spearman en lugar del método pearson para calcular la correlación. Mientras que la correlación de Pearson evalúa la relación lineal entre dos variables continuas, la correlación de Spearman evalúa la
relación monótona en función de los valores clasificados para cada función. Y para ayudar con la interpretación de esta matriz de correlación, usemos .heatmap() de seaborn para visualizarla.
# Crear etiquetas para la matriz de correlación
labels = np.where(np.abs(df_corr) > 0.75,
"S",
np.where(np.abs(df_corr) > 0.5,
"M",
np.where(np.abs(df_corr) > 0.25,
"W",
"")
)
)
# Trazar matriz de correlación
plt.figure(figsize = (15, 15))
sns.heatmap(df_corr,
mask = np.eye(len(df_corr)),
square = True,
center = 0,
annot = labels,
fmt ='',
linewidths = .5,
cmap = "vlag",
cbar_kws = {"shrink": 0.8}
);
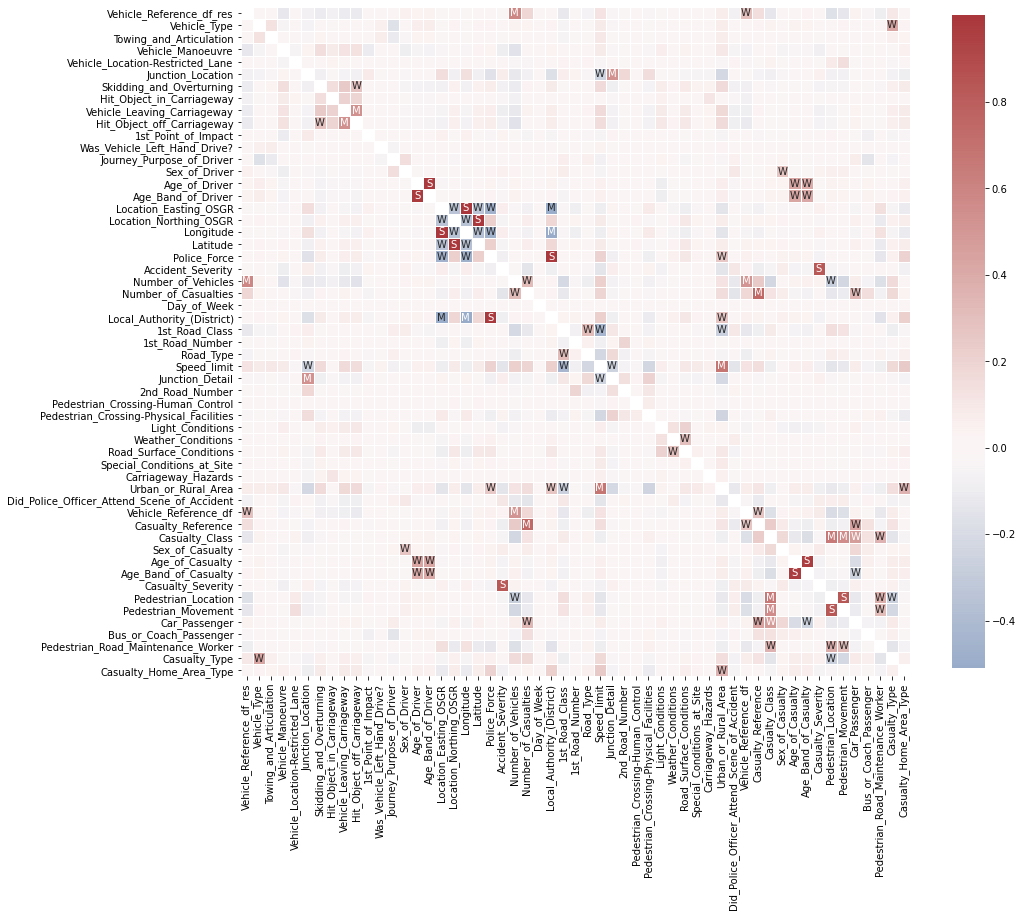
Esto ya parece muy interesante. Podemos ver algunas correlaciones muy fuertes entre algunas de las características. Ahora, si está interesado en ordenar todas estas correlaciones diferentes, podría hacer algo como esto:
# Creates a mask to remove the diagonal and the upper triangle.
lower_triangle_mask = np.tril(np.ones(df_corr.shape),
k = -1).astype("bool")
# Apilar todas las correlaciones, después de aplicar la máscara
df_corr_stacked = df_corr.where(lower_triangle_mask).stack().sort_values()
# Mostrando las correlaciones más bajas y más altas en la matriz de correlación
display(df_corr_stacked)
Local_Authority_(District) Longitude -0.509343
Location_Easting_OSGR -0.502919
Police_Force Longitude -0.471327
Location_Easting_OSGR -0.461112
Speed_limit 1st_Road_Class -0.438931
...
Age_Band_of_Casualty Age_of_Casualty 0.974397
Age_Band_of_Driver Age_of_Driver 0.979019
Local_Authority_(District) Police_Force 0.984819
Longitude Location_Easting_OSGR 0.999363
Latitude Location_Northing_OSGR 0.999974
Length: 1485, dtype: float64
Como puede ver, la investigación de las correlaciones de características puede ser muy informativa. Pero mirar todo a la vez a veces puede ser más confuso que útil. Por lo tanto, centrarse solo en una característica con algo como df_X.corrwith(df_X["Speed_limit"]) podría ser un mejor enfoque.
Además, las correlaciones pueden ser engañosas si una característica todavía contiene muchos valores faltantes o valores atípicos extremos. Por lo tanto, siempre es importante asegurarse primero de que su matriz de funciones esté preparada correctamente antes de investigar estas correlaciones.
Al final de esta tercera investigación, deberíamos tener una mejor comprensión del contenido de nuestro conjunto de datos. Analizamos la distribución de valores, los patrones de características y las correlaciones de características. Sin embargo, estos ciertamente no son todos los pasos posibles de investigación de contenido y limpieza de datos que podría hacer. Los pasos adicionales serían, por ejemplo, la detección y liminación de valores atípicos, la ingeniería y transformación de características, y más.
¡Un EDA adecuado y detallado lleva tiempo! Es un proceso muy iterativo que a menudo lo hace volver al principio, después de abordar otra falla en el conjunto de datos. ¡Esto es normal! Es la razón por la que a menudo decimos que el 80 % de cualquier proyecto de ciencia de datos es preparación de datos y EDA.
Pero también tenga en cuenta que un EDA en profundidad puede consumir mucho tiempo. Y el hecho de que algo parezca interesante no significa que deba darle seguimiento. Recuerde siempre para qué se utilizará el conjunto de datos y adapte sus investigaciones para respaldar ese objetivo. Y a veces también está bien, simplemente hacer una preparación y exploración de datos rápida y sucia. Para que pueda pasar a la parte de modelado de datos con bastante rapidez, y para establecer algunos modelos de referencia preliminares, realice una investigación de resultados informativos.