05 de Agosto del 2022 | Jhonatan Montilla
Realizaremos el análisis del conjunto de datos que contiene seis países diferentes con sus Productos Internos Brutos (PIB) y Expectativas de Vida para los años 2000 a 2015, exploraremos el conjunto de datos, utilizando visualizaciones para comprender mejor la información proporcionada.
El conjunto de datos proporcionado tiene las siguientes columnas de datos:
Con esta información, podremos:
Encuentra si hay una correlación entre las variables dadas Conoce la evolución de la Esperanza de Vida y el PIB a lo largo de los años para cada país Comparar la información entre países
Para lograr nuestros objetivos, necesitaremos buscar algunas respuestas dentro de los datos proporcionados, como:
¿Ha aumentado la esperanza de vida con el tiempo en las seis naciones? ¿Ha aumentado el PIB con el tiempo en las seis naciones? ¿Existe una correlación entre el PIB y la esperanza de vida de un país? ¿Cuál es la esperanza de vida promedio en estas naciones? ¿Cuál es la distribución de esa esperanza de vida? Trabajando con Python y Jupyter Notebook Para este análisis, he usado Jupyter Notebook para escribir códigos de Python y encontrar todas las respuestas a nuestras preguntas previamente definidas. A continuación, traeré los códigos, con algunos comentarios a su alrededor, para mostrar el proceso que he usado durante este EDA.
Primero, tenemos que importar las librerías que vamos a utilizar durante el desarrollo del proyecto:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats
Luego de cargar las librerías, se cargarán los datos con Pandas, hemos decidido reducir el nombre de la columna de “Esperanza de vida al nacer (años)” a sus siglas “LEB”, y cambiar el nombre del país de “Estados Unidos de América” a “USA”, ambas acciones para mejorar la escritura del código.
Podrás descargar el conjunto de datos "life_expectancy_vs_gdp.csv" haciendo clic en el enlace directo a nuestro repositorio.
df = pd.read_csv('life_expectancy_vs_gdp.csv')
df.rename(columns={'Life expectancy at birth (years)': 'LEB'}, inplace=True)
df.replace('United States', 'USA', inplace=True)
countries = df['Country'].unique().tolist()
colors = ['tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown',
'tab:pink', 'tab:olive']
custom_palette = dict([(country, color) for country, color in zip(countries, colors)])
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 96 entries, 0 to 95 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Country 96 non-null object 1 Year 96 non-null int64 2 LEB 96 non-null float64 3 GDP 96 non-null float64 dtypes: float64(2), int64(1), object(1) memory usage: 3.1+ KB
Una de las mejores partes de trabajar con Jupyter para estos análisis es que podemos visualizar rápidamente algunos resultados y tomar decisiones mejores y más rápidas. Por ejemplo, después de ejecutar solo el nombre de la variable, generará automáticamente las primeras y últimas 5 filas del marco de datos y el número total de filas y columnas, sin usar ningún método para hacerlo.
df
| Country | Year | LEB | GDP | |
|---|---|---|---|---|
| 0 | Chile | 2000 | 76.8 | 2.255210e+10 |
| 1 | Chile | 2001 | 76.9 | 2.377458e+10 |
| 2 | Chile | 2002 | 77.4 | 2.482215e+10 |
| 3 | Chile | 2003 | 77.4 | 2.503393e+10 |
| 4 | Chile | 2004 | 77.6 | 2.663641e+10 |
| ... | ... | ... | ... | ... |
| 91 | Zimbabwe | 2011 | 53.3 | 3.433326e+09 |
| 92 | Zimbabwe | 2012 | 55.6 | 3.647860e+09 |
| 93 | Zimbabwe | 2013 | 57.5 | 3.687255e+09 |
| 94 | Zimbabwe | 2014 | 58.8 | 3.775846e+09 |
| 95 | Zimbabwe | 2015 | 59.6 | 3.886050e+09 |
96 rows × 4 columns
En el mismo paso de comprender el conjunto de datos, imprimí la información de sus variables y conté si todos los países dados tenían la misma cantidad de observaciones, para asegurarme de poder compararlos correctamente.
df.describe()
| Year | LEB | GDP | |
|---|---|---|---|
| count | 96.000000 | 96.000000 | 9.600000e+01 |
| mean | 2007.500000 | 72.353125 | 1.093783e+12 |
| std | 4.633971 | 10.931759 | 1.318816e+12 |
| min | 2000.000000 | 42.000000 | 2.577216e+09 |
| 25% | 2003.750000 | 74.100000 | 2.480371e+10 |
| 50% | 2007.500000 | 76.800000 | 3.951206e+11 |
| 75% | 2011.250000 | 78.625000 | 2.540505e+12 |
| max | 2015.000000 | 80.900000 | 3.885245e+12 |
df.Country.value_counts()
Chile 16 China 16 Germany 16 Mexico 16 USA 16 Zimbabwe 16 Name: Country, dtype: int64
Después de cargar, limpiar y comprender el conjunto de datos, pude comenzar a crear gráficos para visualizar y analizar correctamente los datos. Buscando las respuestas a todas las preguntas que definí al inicio del proyecto.
El primer objetivo que definí fue “encontrar si existe una correlación entre las variables dadas”, y el mejor gráfico para correlacionar dos variables numéricas es el diagrama de dispersión. Así que tracé 6 gráficos diferentes para analizar la relación entre la esperanza de vida y el PIB para cada país por separado.
# Define figure grid and its title
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(2, 3, figsize=(10,6))
axs = [ax1, ax2, ax3, ax4, ax5, ax6]
fig.suptitle('Correlation between GDP and Life Expectancy per Country')
for i, (ax, country) in enumerate(zip(axs, countries)):
data = df[df['Country'] == country]
# Plot each graph separated
ax = plt.subplot(2, 3, i + 1)
g = sns.regplot(data, x='GDP', y='LEB', ci=False, color=colors[i])
plt.annotate(country, xy=(0.05, 0.9), xycoords='axes fraction',
bbox=dict(boxstyle="round", fc=colors[i], ec=colors[i], alpha=0.5))
# Find and plot Pearson Correlation (r) for each graph
r = stats.pearsonr(data.GDP, data.LEB)[0]
plt.annotate(f'r = {r :.2f}', xy=(0.05, 0.8), xycoords='axes fraction')
# Transform X-axis in Trillion USD and normalize their ticks
xticks = g.get_xticks()
# xlabels = [tick / 1e12 for tick in xticks]
xlabels = [tick / 1e10 for tick in xticks]
plt.xticks(ticks=xticks[1:-1], labels=xlabels[1:-1])
# Transform Y-axis labels in integers
yticks = [*set([round(tick) for tick in g.get_yticks()])]
g.set(yticks=yticks)
# Remove X and Y labels from graphs in the middle
if ax in [ax1, ax4]:
plt.ylabel('Life Expectancy at Birth (years)')
else:
plt.ylabel('')
if ax in [ax4, ax5, ax6]:
plt.xlabel('GDP (Trillion USD)')
else:
plt.xlabel('')
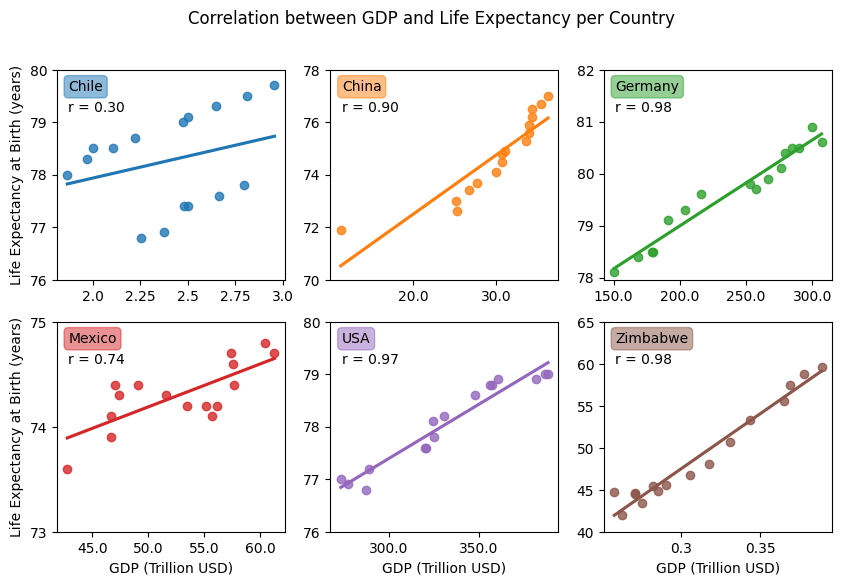
Análisis: Podemos observar una alta correlación entre el PIB y la Esperanza de Vida al Nacer en los 6 casos. Para todos los países, el Coeficiente de Correlación de Pearson (r) fue superior a 0,9, lo que significa una correlación muy alta y positiva entre las variables. Independientemente de la enorme diferencia en el PIB y la esperanza de vida entre cada país, siempre podemos observar la misma correlación positiva alta.
Además de que los gráficos de líneas son las visualizaciones gráficas más simples y comunes, son extremadamente importantes al analizar la evolución de los datos en una línea de tiempo. Dado que nuestro conjunto de datos estaba dividido por países y años, tuve que trazar esta cuadrícula con la evolución individual del PIB y la esperanza de vida para completar el segundo objetivo.
# Define figure grid and its title
fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(3, 2, figsize=(10, 8))
axs = [ax1, ax2, ax3, ax4, ax5, ax6]
fig.suptitle('Evolution of Life Expectancy and GDP per Year in each Country')
for i, (ax, country) in enumerate(zip(axs, countries)):
data = df[df['Country'] == country]
# Plot each graph separated
g1 = plt.subplot(3, 2, i + 1)
plt.annotate(country, xy=(0.05, 0.9), xycoords='axes fraction',
bbox=dict(boxstyle="round", fc=colors[i], ec=colors[i], alpha=0.5))
# Plot Life Expectancy x Year
g1.plot('Year', 'LEB', data=data, color=colors[-2], marker='o')
g1.set_xticks(range(2000, 2016, 3))
# Plot GDP x Year
g2 = g1.twinx()
g2.plot('Year', 'GDP', data=data, color=colors[-1], marker='o')
# Transform LEB-axis labels in integers
leb_ticks = [*set([round(tick) for tick in g1.get_yticks()])]
g1.set(yticks=leb_ticks)
# Transform GDP-axis in Trillion USD and normalize their ticks
gdp_ticks = g2.get_yticks()
gdp_labels = [tick / 1e12 for tick in gdp_ticks]
gdp_labels = [int(tick) if tick % int(tick) == 0 else tick for tick in gdp_labels]
g2.set(yticks=gdp_ticks[1:-1], yticklabels=gdp_labels[1:-1])
# Set Y labels' colors
g1.tick_params(axis='y', colors=colors[-2])
g2.spines['left'].set_color(colors[-2])
g2.tick_params(axis='y', colors=colors[-1])
g2.spines['right'].set_color(colors[-1])
# Remove top spine
g1.spines['top'].set_visible(False)
g2.spines['top'].set_visible(False)
# Set X and Y labels from graphs in the corners
if ax in [ax1, ax3, ax5]:
g1.set_ylabel('Life Expectancy at Birth (years)', color=colors[-2])
if ax in [ax5, ax6]:
g1.set_xlabel('Year')
if ax in [ax2, ax4, ax6]:
g2.set_ylabel('GDP (Trillion USD)', color=colors[-1])
if ax in [ax1, ax2, ax3, ax4]:
g1.set_xticklabels('')
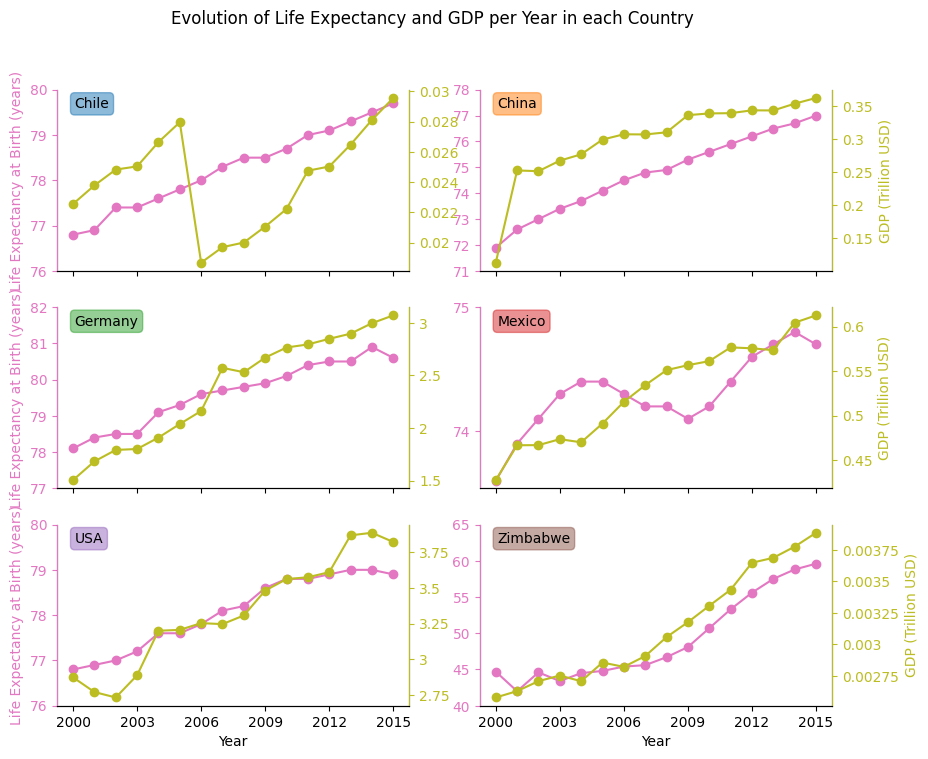
Análisis: Aquí podemos observar un aumento del PIB y de la Esperanza de Vida a lo largo de los años para cada país por separado. Reforzando la correlación entre esas variables.
Después de analizar cada país por separado, decidí graficarlos a todos en el mismo gráfico. Para cada bloque de código a continuación, encontrará los promedios trazados en barras y la línea de evolución trazada al costado, tanto para el PIB como para la Esperanza de Vida. Logrando el tercer objetivo definido, que era “comparar las variables entre países”.
# Define figure grid and its title
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
plt.suptitle('GDP Averages & Evolution per Year')
# Find average GDP for each country
gdp_means = df.groupby('Country')['GDP'].mean().sort_values(ascending=False)
# Bar plot
ax1 = plt.subplot(121)
sns.barplot(x=gdp_means.index, y=gdp_means.values, palette=custom_palette)
# Change Y-axis' label to Trillion USD
ax1.set_ylabel('Average GDP (Trillion USD)')
yticks = ax1.get_yticks()
yticklabels = [round(tick / 1e12) for tick in yticks]
ax1.set(yticks=yticks[:-1], yticklabels=yticklabels[:-1])
# Include values for each bar
for label in ax1.get_xticklabels():
xtick = label.get_position()[0]
xlabel = label.get_text()
ax1.text(x=xtick, y=gdp_means[xlabel] + 0.05e12, s=f"${gdp_means[xlabel] / 1e12 :.2f}T",
horizontalalignment='center')
for country in countries:
data = df[df['Country'] == country]
# Plot lines on second graph
ax2 = plt.subplot(122)
plt.plot(data.Year, data.GDP, marker='o', label=country)
# Change Y-axis' labels and tick values
ax2.set_ylabel('GDP (Trillion USD)')
ax2.set_yticks(ticks=np.arange(0, 18.5e12, 2.5e12), labels=np.arange(0, 18.5, 2.5))
ax2.set_xlabel('Year')
ax2.set_xticks(range(2000, 2016, 3));
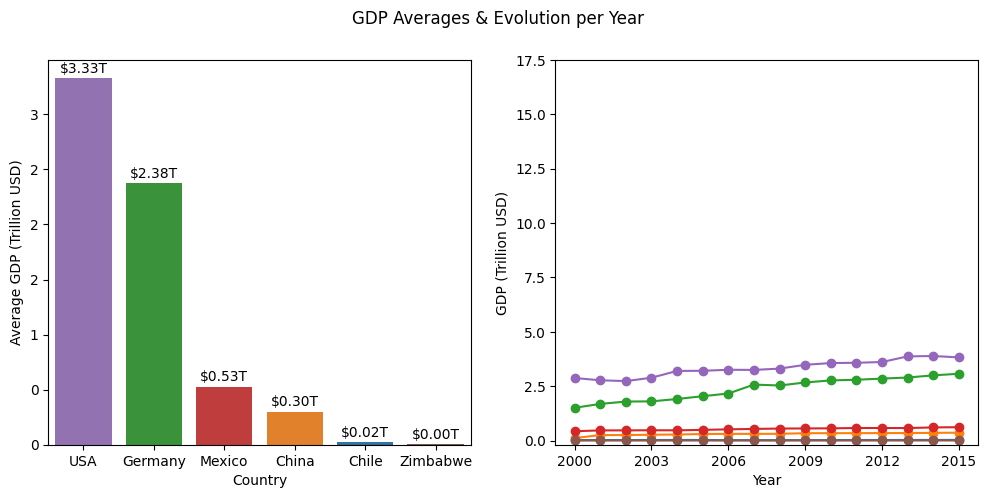
Análisis: Podemos notar una enorme diferencia entre el PIB promedio de Estados Unidos y el resto del grupo. Por ejemplo, los PIB de Zimbabue y Chile parecen ser casi inexistentes en ambos gráficos, dada la escala del gráfico en billones de dólares estadounidenses. Otra observación importante es el crecimiento del PIB chino a lo largo de los años. Comenzando en el 3er lugar y cerca del resto del grupo y creciendo exponencialmente hasta lograr el segundo lugar y divergiendo completamente del grupo inicial, acercándose a los EE. UU.
# Define figure grid and its title
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
plt.suptitle('Life Expectancy Averages & Evolution per Year')
# Find average Life Expectancy for each country
leb_means = df.groupby('Country')['LEB'].mean().sort_values(ascending=False)
# Bar plot
ax1 = plt.subplot(121)
sns.barplot(x=leb_means.index, y=leb_means.values, palette=custom_palette)
ax1.set_ylabel('Average Life Expectancy at Birth (years)')
# Include values for each bar
for label in ax1.get_xticklabels():
xtick = label.get_position()[0]
xlabel = label.get_text()
ax1.text(x=xtick, y=leb_means[xlabel] + 0.5, s=f"{leb_means[xlabel] :.1f}",
horizontalalignment='center')
# Line chart
for country in countries:
data = df[df['Country'] == country]
# Plot lines on second graph
ax2 = plt.subplot(122)
plt.plot(data.Year, data.LEB, marker='o')
ax2.set_ylabel('Life Expectancy at birth (years)')
ax2.set_xlabel('Year');
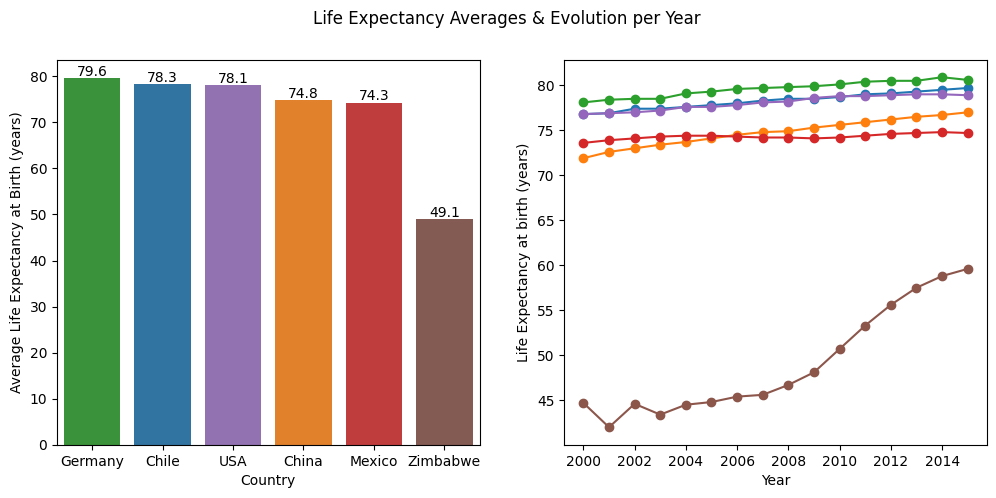
Análisis: trazar la esperanza de vida de cada país en el mismo gráfico muestra una gran diferencia entre Zimbabue, que tiene un promedio de 50 años de vida, y los otros países, que tienen un promedio de alrededor de 77 años de vida. Esta distancia es muy alarmante y genera preocupaciones sobre la calidad de vida del país.
Durante la fase de alcance del proyecto, definí los objetivos y algunos análisis que pensé que serían útiles para lograr esos objetivos. Uno de esos análisis fue encontrar la distribución de la variable, pero confieso que analizar solo la distribución no fue tan esclarecedor. Sin embargo, incluso cuando haces algo que no vas a usar, a veces tienes nuevas ideas que pueden ser interesantes. Y mientras graficaba la distribución, pensé que sería bueno dibujar un diagrama de caja con todos los países conjugados y analizar la evolución de todo el grupo por año.
# Define figure grid and its title
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
fig.suptitle('Evolution of GDP & Life Expectancy Distributions per Year')
# Box plot: GDP per Year
axs[0] = plt.subplot(121)
g1 = sns.boxplot(data=df, x='Year', y='GDP')
g1.set_ylabel('GDP (Trillion USD)')
plt.xticks(rotation=45)
# Change Y-axis labels to the Trillion scale
yticks = g1.get_yticks()
ylabels = [tick / 1e12 for tick in yticks]
plt.yticks(ticks=yticks[1:-1], labels=ylabels[1:-1])
# Show median values in the graph
g1_medians = df.groupby(df['Year'])['GDP'].median()
g1_medians = [median / 1e12 for median in g1_medians]
for xtick in g1.get_xticks():
g1.text(xtick, g1_medians[xtick] * 1.1e12, f'{g1_medians[xtick] :.2f}',
horizontalalignment='center',size='x-small',color='w',weight='semibold')
# Box plot: Life Expectancy at Birth per Year
axs[1] = plt.subplot(122)
g2 = sns.boxplot(data=df, x='Year', y='LEB')
g2.set_ylabel('Life Expectancy at Birth (years)')
plt.xticks(rotation=45)
# Show median values in the graph
g2_medians = df.groupby(df['Year'])['LEB'].median()
for xtick in g2.get_xticks():
g2.text(xtick, g2_medians.iloc[xtick] + 0.3, f'{g2_medians.iloc[xtick] :.1f}',
horizontalalignment='center',size='x-small',color='w',weight='semibold');
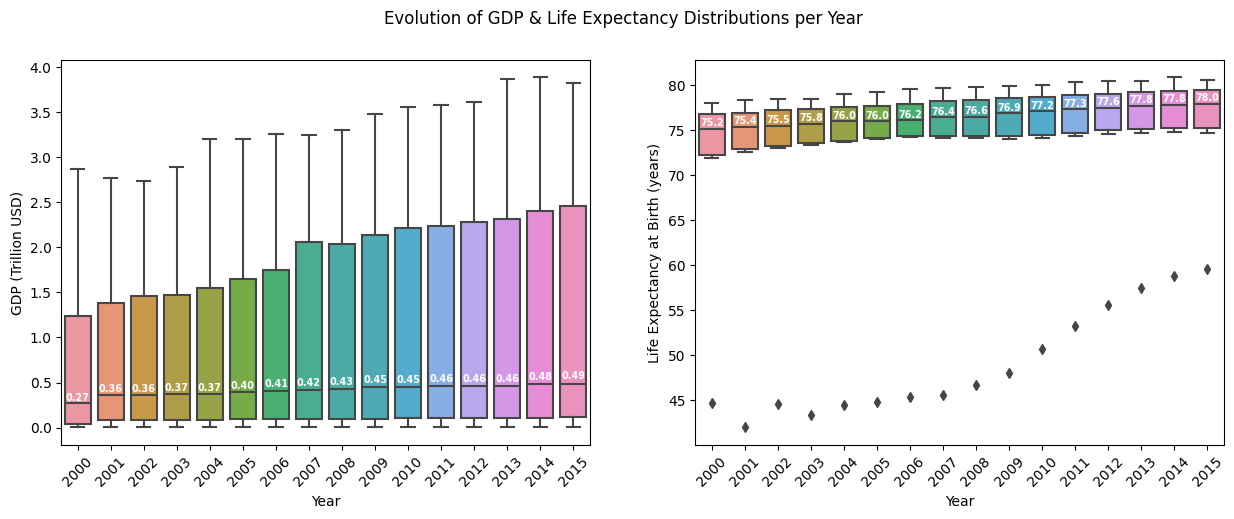
Análisis: En el primer gráfico, podemos ver un aumento en el PIB mediano hasta 2008. Luego, en 2009 podemos observar una disminución en el PIB general, reflejo de la crisis financiera de 2008, y cierta dificultad de la mediana para volver a la pista hasta el final del gráfico. Además, es notable el valor atípico del límite superior, lo que muestra que Estados Unidos está muy lejos del resto de los países en términos de PIB. Una última observación es que el rango intercuartílico ha aumentado año tras año. Dándonos la falsa sensación de que los demás países se estaban acercando a los EE.UU. Pero cuando analizamos los gráficos individuales, podemos ver que en realidad es el PIB chino el que crece fuera del grupo del límite inferior y se acerca, por sí solo, al PIB estadounidense.
En el segundo gráfico podemos observar un aumento de la mediana de la Esperanza de Vida a lo largo de los años, así como una disminución del rango intercuartílico. Esto significa que las esperanzas de vida de los países en este conjunto de datos aumentaban y se acercaban cada año. Es notorio por los valores atípicos de límite inferior en este gráfico, que muestran que la esperanza de vida de Zimbabue es muy discordante con el resto de los países en este conjunto de datos.
Una de las partes más interesantes de hacer un análisis exploratorio de datos es que siempre tienes nuevas ideas, piensas en nuevas hipótesis y te preguntas si hay más información oculta dentro de esas observaciones.
Mientras realizaba este análisis y me acercaba a (lo que pensé que sería) el final, obtuve otro avance: "¿qué pasa con la tasa de crecimiento de cada país?"
Como se vio antes, todos los países crecieron en términos de PIB y Esperanza de Vida. Además, encontramos una correlación positiva entre estos índices. Y, a pesar de las diferencias entre ellos, ¿qué pasa si nos fijamos en su crecimiento individual para este período?
Aquí empiezo creando un nuevo Data Frame con la información que busco, la tasa de crecimiento de cada país para ambas variables.
df_growth = df.sort_values(by='Year').groupby('Country')\
.agg(gdp_growth=('GDP', lambda x: (x.iloc[-1] - x.iloc[0]) / x.iloc[0]),
leb_growth=('LEB', lambda x: (x.iloc[-1] - x.iloc[0]) / x.iloc[0]))
display(df_growth)
| gdp_growth | leb_growth | |
|---|---|---|
| Country | ||
| Chile | 0.310557 | 0.037760 |
| China | 2.211223 | 0.070932 |
| Germany | 1.038317 | 0.032010 |
| Mexico | 0.432843 | 0.014946 |
| USA | 0.329850 | 0.027344 |
| Zimbabwe | 0.507848 | 0.333333 |
Los números son geniales, pero son mejores cuando podemos visualizarlos de alguna forma. Por eso dibujo dos gráficos más para ver esta información en conjunto y poder compararlos.
# Define figure grid and its title
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
fig.suptitle('GDP & Life Expectancy Growth Between 2000-2015')
# Plot GDP Bar Graph
ax1 = plt.subplot(121)
order =
[country for country in df_growth.sort_values(by='gdp_growth', ascending=False).index]
sns.barplot(x=df_growth.index, y=df_growth.gdp_growth, palette=custom_palette, order=order)
# Set Y-axis' labels to percentage
ax1.set_ylabel('Gross Domestic Product (GDP)')
yticks = ax1.get_yticks()
ylabels = [f'{tick * 100 :.0f}%' for tick in yticks]
ax1.set(yticks=yticks[:-1], yticklabels=ylabels[:-1])
# Include values for each bar
for label in ax1.get_xticklabels():
xtick = label.get_position()[0]
xlabel = label.get_text()
ax1.text(x=xtick, y=df_growth.loc[xlabel, 'gdp_growth'] + 0.05,
s=f"{df_growth.loc[xlabel, 'gdp_growth'] * 100 :.1f}%", horizontalalignment='center')
# Plot Life Expectancy Bar Graph
ax2 = plt.subplot(122)
order =
[country for country in df_growth.sort_values(by='leb_growth', ascending=False).index]
sns.barplot(x=df_growth.index, y=df_growth.leb_growth, palette=custom_palette, order=order)
# Set Y-axis' labels to percentage
ax2.set_ylabel('Life Expectancy at Birth')
yticks = ax2.get_yticks()
ylabels = [f'{tick * 100 :.0f}%' for tick in yticks]
ax2.set(yticks=yticks[:-1], yticklabels=ylabels[:-1])
# Include values for each bar
for label in ax2.get_xticklabels():
xtick = label.get_position()[0]
xlabel = label.get_text()
ax2.text(x=xtick, y=df_growth.loc[xlabel, 'leb_growth'] + 0.002,
s=f"{df_growth.loc[xlabel, 'leb_growth'] * 100 :.1f}%", horizontalalignment='center');
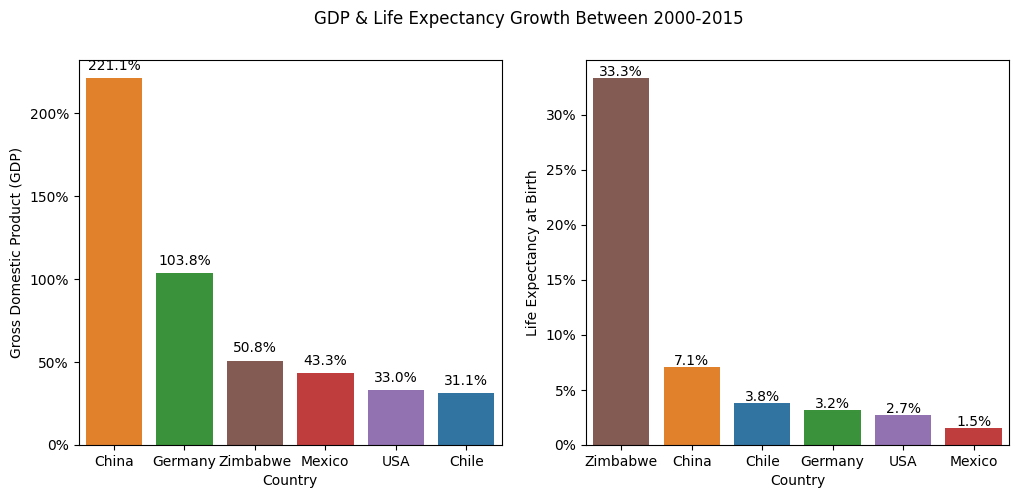
Análisis: En el primer gráfico, China llama nuestra atención al mostrar un crecimiento del PIB de más del 800 % entre 2000 y 2015, casi 4 veces más que el segundo lugar y 12 veces más que el último. Esto es realmente impresionante, dado que al principio estaban cerca del resto del grupo, como se vio antes. También podemos comentar que China ocupa el segundo lugar en el crecimiento de la Esperanza de Vida, lo que refuerza el factor de correlación entre esos índices.
En cuanto al crecimiento de la esperanza de vida, Zimbabue ahora llama la atención con un crecimiento del 32% durante 15 años, 5 veces más que China y casi 13 veces más que México. Lo cual es magnífico, especialmente dado que estaba muy lejos del resto del grupo.
En este caso de estudio, se mostró nuevamente un EDA sobre un conjunto de datos determinado para nuestro caso particular, sin embargo, esta misma metodología se sugiere usar para cualquier conjunto de datos que se tenga en cualquier otro caso particular.