Análisis Exploratorio de Datos (EDA)
Publicado el: 07 de Diciembre del 2020 - Jhonatan Montilla
Análisis de datos de ventas en tiendas Walmart.
Planteamiento del Problema.
Walmart, es una cadena de tiendas minoristas líder en los EE.UU., la empresa desea predecir las ventas de productos en sus tiendas con cierta precisión. Ciertos eventos y días festivos afectan las ventas de cada día. Se tienen disponible los datos de ventas de 45 tiendas. La empresa enfrenta un desafío debido a demandas imprevistas y se agotan los inventarios en ocasiones debido al cálculo generado por un algoritmo de aprendizaje automático (ML) inadecuado. Un algoritmo de ML ideal deberá predecir la demanda con precisión incorporando factores como las condiciones económicas, incluido el IPC, el índice de desempleo, etc.
La empresa Walmart organiza varios eventos promocionales de rebajas durante todo el año. Estas rebajas preceden a los feriados importantes, los cuatro más grandes de todos, que son el Super Bowl, el Día del Trabajador, el Día de Acción de Gracias y la Navidad. Las semanas que incluyen estos días festivos se ponderan cinco veces más en la evaluación que las semanas que no son festivos. Parte del desafío es modelar los efectos de las rebajas en estas semanas de vacaciones en ausencia de datos históricos completos.
Descripción del conjunto de datos¶
Estos son los datos históricos que cubren las ventas de 2010–02–05 a 2012–11–01, en el archivo Walmart_Store_sales. Dentro de este archivo encontrará los siguientes campos:
- Tienda: Número de la tienda
- Fecha: Semana de ventas
- Weekly_Sales: Ventas para la tienda determinada
- Holiday_Flag: Si la semana es una semana festiva especial, 1: Semana festiva, 0: Semana no festiva
- Temperatura: Temperatura el día de la venta
- Fuel_Price: Costo del combustible en la región
- IPC: Índice de precios al consumidor predominante
- Desempleo: Tasa de desempleo predominante
Eventos festivos
- Super Bowl: 12-feb-10, 11-feb-11, 10-feb-12, 8-feb-13
- Día del Trabajo: 10-septiembre-10, 9-septiembre-11, 7-septiembre-12, 6-septiembre-13
- Acción de Gracias: 26-nov-10, 25-nov-11, 23-nov-12, 29-nov-13
- Navidad: 31-dic-10, 30-dic-11, 28-dic-12, 27-dic-13
Tareas de análisis¶
1- ¿Qué tienda tiene ventas máximas?.
2- ¿Qué tienda tiene la desviación estándar máxima, es decir, las ventas varían mucho. Además, averigüe el coeficiente de varianza?.
3- ¿Qué tienda tiene una buena tasa de crecimiento trimestral en el tercer trimestre de 2012?.
4- Algunas vacaciones tienen un impacto negativo en las ventas. Determine los días festivos que tienen las ventas más altas que las ventas medias en la temporada no festiva para todas las tiendas juntas.
5- Proporcione una vista mensual y semestral de las ventas en unidades y brinde información.
PASO 1: - Importar las bibliotecas necesarias.
import pandas as pd
from datetime import date
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
PASO 2: - Descargar e importar el conjunto de datos a través del siguiente enlace al repositorio.
data = pd.read_csv ('walmart_store_sales.csv')
PASO 3: - Muestra parcial del conjunto de datos.
data.head()
| Store | Date | Weekly_Sales | Holiday_Flag | Temperature | Fuel_Price | CPI | Unemployment | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 05-02-2010 | 1643690.90 | 0 | 42.31 | 2.572 | 211.096358 | 8.106 |
| 1 | 1 | 12-02-2010 | 1641957.44 | 1 | 38.51 | 2.548 | 211.242170 | 8.106 |
| 2 | 1 | 19-02-2010 | 1611968.17 | 0 | 39.93 | 2.514 | 211.289143 | 8.106 |
| 3 | 1 | 26-02-2010 | 1409727.59 | 0 | 46.63 | 2.561 | 211.319643 | 8.106 |
| 4 | 1 | 05-03-2010 | 1554806.68 | 0 | 46.50 | 2.625 | 211.350143 | 8.106 |
En la tabla anterior se puede observar la información básica contenida en el conjunto de datos
A continuación se muestran los tipos de variables contenidas en el conjunto de datos.
data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 6435 entries, 0 to 6434 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Store 6435 non-null int64 1 Date 6435 non-null object 2 Weekly_Sales 6435 non-null float64 3 Holiday_Flag 6435 non-null int64 4 Temperature 6435 non-null float64 5 Fuel_Price 6435 non-null float64 6 CPI 6435 non-null float64 7 Unemployment 6435 non-null float64 dtypes: float64(5), int64(2), object(1) memory usage: 402.3+ KB
A continuación se muestran los valores máximos para cada una de las variables.
data.max()
Store 45 Date 31-12-2010 Weekly_Sales 3818686.45 Holiday_Flag 1 Temperature 100.14 Fuel_Price 4.468 CPI 227.232807 Unemployment 14.313 dtype: object
PREGUNTA 1: ¿Cuál tienda tiene las ventas máximas en este conjunto de datos?
data.loc[data['Weekly_Sales'] == data['Weekly_Sales'].max()]
| Store | Date | Weekly_Sales | Holiday_Flag | Temperature | Fuel_Price | CPI | Unemployment | |
|---|---|---|---|---|---|---|---|---|
| 1905 | 14 | 24-12-2010 | 3818686.45 | 0 | 30.59 | 3.141 | 182.54459 | 8.724 |
Los resultados obtenidos anteriormente muestran que la Tienda número 14 tiene el máximo de ventas semanales.
PREGUNTA 2: ¿Cuál tienda tiene la desviación estándar máxima?.
La pregunta consiste en determinar, en cual tienda las ventas varían significativamente. Además, se debe determinar el coeficiente de varianza (COV), COV es la relación entre la desviación estándar y la media.
Se deben agrupar los datos por tienda para determinar la media y la desviación estándar.
maxstd = pd.DataFrame(data.groupby('Store').agg({'Weekly_Sales':['std','mean']}))
axstd = maxstd.reset_index() # Restableciendo el índice de la agrupación.
Se debe crear una nueva variable que contenga los datos calculados de COV para cada tienda.
maxstd['CoV'] = round(((maxstd[('Weekly_Sales','std')]/maxstd[('Weekly_Sales','mean')]) *100),2)
El próximo paso es determinar la tienda con las ventas de mayor variación (COV)
maxstd.loc[maxstd[('Weekly_Sales','std')] == maxstd[('Weekly_Sales','std')].max()]
| Weekly_Sales | CoV | ||
|---|---|---|---|
| std | mean | ||
| Store | |||
| 14 | 317569.949476 | 2.020978e+06 | 15.71 |
Del resultado obtenido anteriormente se concluye que la tienda con el mayor número de variación de sus ventas corresponde a la tienda número 14.
PREGUNTA 3: ¿Cuál(es) tienda(s) tiene(n) una buena tasa de crecimiento trimestral en el tercer trimestre del 2012?.
Lo primero que se debe ejecutar es la conversión de los datos contenido en la variable Date a formato de Fecha (DateTime).
data['Date'] = pd.to_datetime(data['Date'])
Se definen el inicio y término de los trimestres Q2 y Q3
Q2_date_from = pd.Timestamp(date(2012,4,1))
Q2_date_to = pd.Timestamp(date(2012,6,30))
Q3_date_from = pd.Timestamp(date(2012,7,1))
Q3_date_to = pd.Timestamp(date(2012,9,30))
Se procede a obtener los datos del dataset correspondientes a los trimestres Q2 y Q3
Q2data = data[(data['Date'] > Q2_date_from) & (data['Date'] < Q2_date_to)]
Q3data = data[(data['Date'] > Q3_date_from) & (data['Date'] < Q3_date_to)]
Se procede a obtener la suma de las ventas semanales de cada tienda en el segundo trimestre (Q2).
Q2 = pd.DataFrame(Q2data.groupby('Store')['Weekly_Sales'].sum())
Q2.reset_index(inplace=True)
Q2.rename(columns={'Weekly_Sales': 'Q2_Weekly_Sales'},inplace=True)
Se procede a obtener la suma de las ventas semanales de cada tienda en el tercer trimestre (Q3).
Q3 = pd.DataFrame(Q3data.groupby('Store')['Weekly_Sales'].sum())
Q3.reset_index(inplace=True)
Q3.rename(columns={'Weekly_Sales': 'Q3_Weekly_Sales'},inplace=True)
Se fusionan los datos obtenidos de Q2 y Q3
Q3_Growth= Q2.merge(Q3,how='inner',on='Store')
La ecuación que define la tasa de crecimiento se establece como la relación entre la diferencia del valor presente y el valor pasado dividido entre el valor pasado total multiplicado por 100, para determinar el porcentaje.
((Valor Presente - Valor Pasado) / Valor Pasado) * 100
Por lo tanto, se procede a crear una variable en el dataset con el valor de crecimiento de las ventas para cada tienda.
Q3_Growth['Growth_Rate'] =(Q3_Growth['Q3_Weekly_Sales'] - Q3_Growth['Q2_Weekly_Sales'])/Q3_Growth['Q2_Weekly_Sales']
Q3_Growth['Growth_Rate'] = round(Q3_Growth['Growth_Rate'],2) # Redondea a dos dígitos
Siguiente paso, determinar la tienda con la menor tasa de crecimiento de sus ventas para el tercer trimestre Q3
Q3_Growth.sort_values('Growth_Rate',ascending=False).head(1)
| Store | Q2_Weekly_Sales | Q3_Weekly_Sales | Growth_Rate | |
|---|---|---|---|---|
| 15 | 16 | 6626133.44 | 6441311.11 | -0.03 |
Siguiente paso, determinar la tienda con la mayor tasa de crecimiento de sus ventas para el tercer trimestre Q3
Q3_Growth.sort_values('Growth_Rate',ascending=False).tail(1)
| Store | Q2_Weekly_Sales | Q3_Weekly_Sales | Growth_Rate | |
|---|---|---|---|---|
| 13 | 14 | 24427769.06 | 20140430.4 | -0.18 |
De los resultados obtenidos anteriormente se puede concluir que la tasa de crecimiento del tercer trimestre Q3 fue negativo (en pérdida).
- La tienda número 16 obtuvo la menor pérdida: -3%
- La tienda número 14 obtuvo la mayor pérdida: -18%
PREGUNTA 4: Algunas vacaciones tienen un impacto negativo en las ventas. Determinar los días festivos donde se obtienen mayores ventas que las ventas promedio en la temporada no festiva para todas las tiendas.
Primeramente se determinan las ventas promedio de los días festivos y no festivos.
data.groupby('Holiday_Flag')['Weekly_Sales'].mean()
Holiday_Flag 0 1.041256e+06 1 1.122888e+06 Name: Weekly_Sales, dtype: float64
Se procede a establecer las fechas correspondientes a los días festivos
Christmas1 = pd.Timestamp(date(2010,12,31) )
Christmas2 = pd.Timestamp(date(2011,12,30) )
Christmas3 = pd.Timestamp(date(2012,12,28) )
Christmas4 = pd.Timestamp(date(2013,12,27) )
Thanksgiving1=pd.Timestamp(date(2010,11,26) )
Thanksgiving2=pd.Timestamp(date(2011,11,25) )
Thanksgiving3=pd.Timestamp(date(2012,11,23) )
Thanksgiving4=pd.Timestamp(date(2013,11,29) )
LabourDay1=pd.Timestamp(date(2010,2,10) )
LabourDay2=pd.Timestamp(date(2011,2,9) )
LabourDay3=pd.Timestamp(date(2012,2,7) )
LabourDay4=pd.Timestamp(date(2013,2,6) )
SuperBowl1=pd.Timestamp(date(2010,9,12) )
SuperBowl2=pd.Timestamp(date(2011,9,11) )
SuperBowl3=pd.Timestamp(date(2012,9,10) )
SuperBowl4=pd.Timestamp(date(2013,9,8) )
Próximo paso, calcular las ventas promedio durante los días festivos.
Christmas_mean_sales=data[(data['Date'] == Christmas1) | (data['Date'] == Christmas2) | (data['Date'] == Christmas3) | (data['Date'] == Christmas4)]
Thanksgiving_mean_sales=data[(data['Date'] == Thanksgiving1) | (data['Date'] == Thanksgiving2) | (data['Date'] == Thanksgiving3) | (data['Date'] == Thanksgiving4)]
LabourDay_mean_sales=data[(data['Date'] == LabourDay1) | (data['Date'] == LabourDay2) | (data['Date'] == LabourDay3) | (data['Date'] == LabourDay4)]
SuperBowl_mean_sales=data[(data['Date'] == SuperBowl1) | (data['Date'] == SuperBowl2) | (data['Date'] == SuperBowl3) | (data['Date'] == SuperBowl4)]
list_of_mean_sales = {'Christmas_mean_sales' : round(Christmas_mean_sales['Weekly_Sales'].mean(),2),
'Thanksgiving_mean_sales': round(Thanksgiving_mean_sales['Weekly_Sales'].mean(),2),
'LabourDay_mean_sales' : round(LabourDay_mean_sales['Weekly_Sales'].mean(),2),
'SuperBowl_mean_sales':round(SuperBowl_mean_sales['Weekly_Sales'].mean(),2),
'Non holiday weekly sales' : round((data[data['Holiday_Flag'] == 0 ]['Weekly_Sales'].mean()),2)}
list_of_mean_sales
{'Christmas_mean_sales': 960833.11,
'Thanksgiving_mean_sales': 1471273.43,
'LabourDay_mean_sales': 1008369.41,
'SuperBowl_mean_sales': nan,
'Non holiday weekly sales': 1041256.38}
De los resultados obtenidos anteriormente se puede concluir que las ventas promedios realizadas durante el feriado Día de Acción de Gracias, es mayor que las ventas semanales no festivas.
PREGUNTA 5: Proporcione con comentarios analíticos una vista mensual, trimestral y semestral de las ventas en unidades.
- Gráfico Mensual
monthly = data.groupby(pd.Grouper(key='Date', freq='1M')).sum() # Agrupa los datos por mes
monthly=monthly.reset_index()
fig, ax = plt.subplots(figsize=(10,8))
X = monthly['Date']
Y = monthly['Weekly_Sales']
plt.plot(X,Y)
plt.title('Ventas Mensuales')
plt.xlabel('Meses')
plt.ylabel('Ventas Semanales (En millones de USD)');
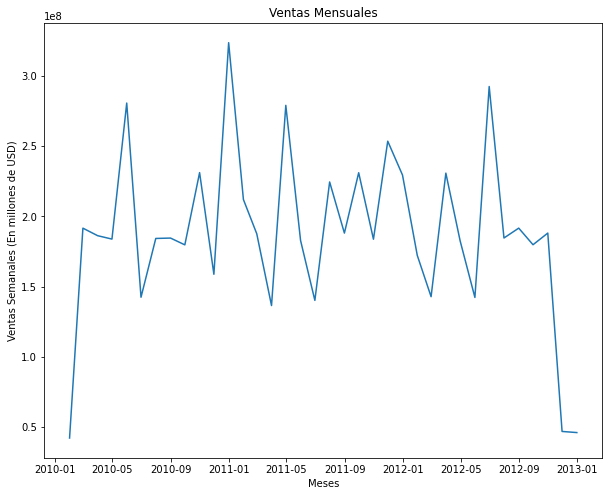
Se puede observar en el gráfico de ventas mensuales que los mayores registros de ventas se obtuvieron entre los meses de Enero 2011 y Julio 2012.
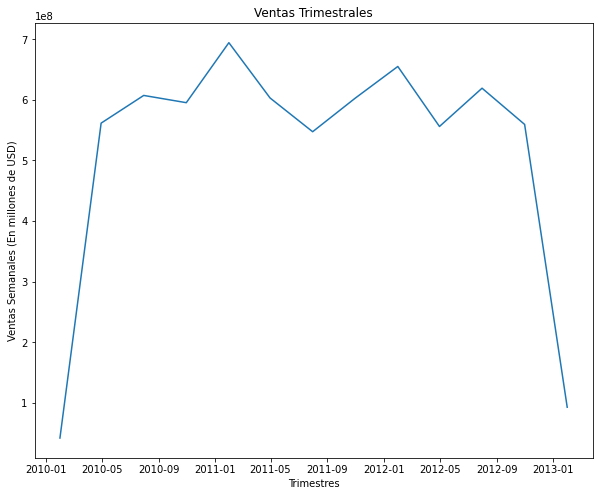
- Gráfico Trimestral
Quaterly = data.groupby(pd.Grouper(key='Date', freq='3M')).sum() # Agrupa los datos por trimestres
Quaterly = Quaterly.reset_index()
fig, ax = plt.subplots(figsize=(10,8))
X = Quaterly['Date']
Y = Quaterly['Weekly_Sales']
plt.plot(X,Y)
plt.title('Ventas Trimestrales')
plt.xlabel('Trimestres')
plt.ylabel('Ventas Semanales (En millones de USD)');
Quaterly.head(10)
| Date | Store | Weekly_Sales | Holiday_Flag | Temperature | Fuel_Price | CPI | Unemployment | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2010-01-31 | 1035 | 4.223988e+07 | 0 | 3144.06 | 123.045 | 7575.961790 | 381.388 |
| 1 | 2010-04-30 | 12420 | 5.616249e+08 | 0 | 30152.46 | 1517.442 | 90668.190883 | 4603.421 |
| 2 | 2010-07-31 | 13455 | 6.073143e+08 | 0 | 38886.30 | 1646.360 | 98241.900375 | 4968.652 |
| 3 | 2010-10-31 | 13455 | 5.953623e+08 | 45 | 39054.88 | 1640.944 | 98436.182932 | 4944.339 |
| 4 | 2011-01-31 | 14490 | 6.943104e+08 | 135 | 29278.66 | 1920.567 | 106369.690587 | 5296.918 |
| 5 | 2011-04-30 | 13455 | 6.030990e+08 | 0 | 31273.71 | 2071.638 | 100045.255668 | 4772.415 |
| 6 | 2011-07-31 | 12420 | 5.474564e+08 | 0 | 37317.61 | 2018.925 | 92523.508979 | 4382.378 |
| 7 | 2011-10-31 | 13455 | 6.028326e+08 | 45 | 39341.09 | 2112.421 | 100765.181291 | 4688.981 |
| 8 | 2012-01-31 | 13455 | 6.550670e+08 | 135 | 28096.00 | 2009.493 | 101326.042029 | 4565.239 |
| 9 | 2012-04-30 | 12420 | 5.561121e+08 | 0 | 30261.33 | 2041.429 | 94609.439676 | 4026.321 |
Se puede observar en el gráfico de ventas trimestrales que los mayores registros de ventas se obtuvieron entre los trimestres de Q1 2011 y Q1 2012.
- Gráfico Semestral
Semester = data.groupby(pd.Grouper(key='Date', freq='6M')).sum() # Agrupa los datos por semestres
Semester = Semester.reset_index()
fig, ax = plt.subplots(figsize=(10,8))
X = Semester['Date']
Y = Semester['Weekly_Sales']
plt.plot(X,Y)
plt.title('Ventas Semestrales')
plt.xlabel('Semestre')
plt.ylabel('Ventas Semanales (En millones de USD)');
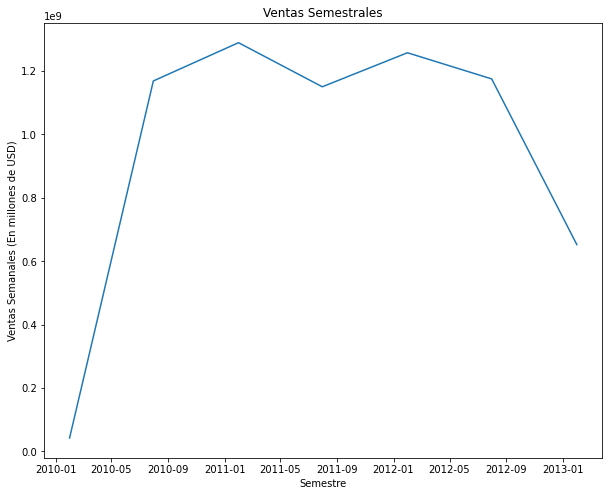
Se puede observar en el gráfico de ventas semestrales que los mayores registros de ventas se obtuvieron entre los semestres de S1 2011 y S1 2012.