Análisis de Datos Financieros con Python
02 de Diciembre del 2020 - Jhonatan Montilla
En este apartado se analizarán los precios de las acciones de tres empresas: Amazon (AMZN), Google (GOOGL) y Apple (AAPL). Se realizará un análisis de datos exploratorio simple de estas acciones mediante la generación de visualizaciones y estadísticas resumidas, análisis de riesgo y rendimiento, y la generación de indicadores rezagados para comprender las tendencias de los precios de las acciones. Esto debería formar una base sólida para el principiante que quiera comenzar a aprender a analizar datos financieros en Python. Antes de comenzar, estas son algunas de las herramientas que usaremos.
Pandas-datareader es una biblioteca de Python que permite a los usuarios acceder fácilmente a los datos de precios de las acciones y realizar tareas de análisis estadístico como calcular retornos, riesgos, promedios móviles y más. Además, matplotlib y seaborn son bibliotecas en Python que le permiten crear visualizaciones de datos como diagramas de caja y diagramas de series de tiempo. La combinación de estas bibliotecas permite a los científicos de datos obtener información valiosa de los datos financieros con relativamente pocas líneas de código.
El análisis de riesgo de las acciones es importante para comprender la incertidumbre en la fluctuación del precio de las acciones. Esto puede ayudar a los inversores a elegir en qué acciones les gustaría invertir en función de su tolerancia al riesgo. Podemos utilizar cálculos de promedio móvil para informar aún más las decisiones de inversión mediante la descripción de la tendencia direccional en el movimiento del precio de las acciones.
Por último, los gráficos de la banda de Bollinger son una forma útil de visualizar la volatilidad de los precios. Los gráficos de la banda de Bollinger y los promedios móviles son lo que llamamos indicadores rezagados. Esto significa que se basan en cambios a largo plazo y nos ayudan a comprender las tendencias a largo plazo. Esto contrasta con los indicadores adelantados que se utilizan para predecir futuros movimientos de precios.
Acceder a datos financieros mediante Pandas-Datareader¶
Para comenzar, es necesario instalar la biblioteca pandas-datareader usando el siguiente comando en la terminal:
pip install pandas-datareader
A continuación, importar el objeto web desde el módulo pandas_datareader.data. También importar el paquete datetime integrado que permitirá crear objetos datetime de Python:
import pandas_datareader.data as web
import datetime
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import seaborn as sns
Se extráen los datos de precios de acciones para Amazon, se almacenan en una variable llamada amzn, se visualizan las primeras cinco filas de datos:
amzn = web.DataReader("AMZN","yahoo")
amzn.head()
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-07-25 | 748.500000 | 735.349976 | 746.549988 | 739.609985 | 2679300 | 739.609985 |
| 2016-07-26 | 743.130005 | 732.750000 | 742.710022 | 735.590027 | 2529700 | 735.590027 |
| 2016-07-27 | 740.940002 | 733.859985 | 737.969971 | 736.669983 | 2913100 | 736.669983 |
| 2016-07-28 | 753.359985 | 739.700012 | 745.979980 | 752.609985 | 7617600 | 752.609985 |
| 2016-07-29 | 766.000000 | 755.000000 | 765.000000 | 758.809998 | 6777100 | 758.809998 |
Se observa que el dataset contiene las columnas: Alto, Bajo, Abierto, Cerrado, Volumen y Cierre ajustado. Estos valores se basan en los precios de las acciones durante una sesión de negociación que suele ser entre las 9:30 am y las 4:00 pm. Se considera que cada columna significa:
-
Precio alto: el precio más alto de una acción durante una sesión de negociación.
-
Precio bajo: el precio más bajo de una acción durante una sesión de negociación.
-
Precio de cierre: el precio de una acción al final de una sesión de negociación.
-
Precio de apertura: el precio de una acción al comienzo de una sesión de negociación.
-
Cierre ajustado: el precio de cierre después de realizar ajustes por división de acciones y dividendos.
El siguiente paso consiste en guardar estos datos en un archivo .csv utilizando el método pandas to_csv:
amzn.to_csv("amzn_data_financiera.csv", index=True)
Una vez guardado los datos datos de AMZN, se extráen los datos para GOOGLE y APPLE. Primero GOOGLE y luego AAPL.
googl = web.DataReader("GOOGL","yahoo")
googl.head()
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-07-25 | 759.820007 | 754.070007 | 757.679993 | 757.520020 | 1073300 | 757.520020 |
| 2016-07-26 | 759.260010 | 752.750000 | 757.520020 | 757.650024 | 1189600 | 757.650024 |
| 2016-07-27 | 764.450012 | 755.929993 | 758.969971 | 761.969971 | 1608600 | 761.969971 |
| 2016-07-28 | 768.969971 | 759.090027 | 768.840027 | 765.840027 | 3673200 | 765.840027 |
| 2016-07-29 | 803.940002 | 790.000000 | 797.710022 | 791.340027 | 5090500 | 791.340027 |
googl.to_csv("googl_data_financiera.csv", index=True)
A continuación, AAPL:
aapl = web.DataReader("AAPL","yahoo")
aapl.head()
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-07-25 | 24.709999 | 24.2300 | 24.562500 | 24.334999 | 161531600.0 | 22.733387 |
| 2016-07-26 | 24.492500 | 24.1050 | 24.205000 | 24.167500 | 224959200.0 | 22.576918 |
| 2016-07-27 | 26.087500 | 25.6875 | 26.067499 | 25.737499 | 369379200.0 | 24.043583 |
| 2016-07-28 | 26.112499 | 25.7050 | 25.707500 | 26.084999 | 159479200.0 | 24.368214 |
| 2016-07-29 | 26.137501 | 25.9200 | 26.047501 | 26.052500 | 110934800.0 | 24.337851 |
aapl.to_csv("aapl_data_financiera.csv", index=True)
Ahora se tienen almacenados tres archivos que contienen dos años con los precios de acciones para AMZN, GOOGL y AAPL. Se procede a leer estos archivos y almacenarlos en nuevos dataset utilizando pandas:
amzn_df = pd.read_csv("amzn_data_financiera.csv")
googl_df = pd.read_csv("googl_data_financiera.csv")
aapl_df = pd.read_csv("aapl_data_financiera.csv")
Exploración y visualización de datos financieros¶
A continuación, se generan algunos datos estadísticos simples. Una métrica importante para comprender los movimientos del precio de las acciones es su rendimiento. El retorno se define como el precio de apertura menos el precio de cierre dividido por el precio de apertura (R = [apertura-cierre] / apertura). Se calculan los retornos para cada empresa.
Se calculan los retornos diarios de AMZN:
amzn_df["Returns"] = (amzn_df["Close"] - amzn_df["Open"])/amzn_df["Open"]
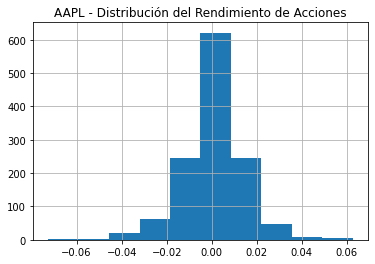
Una visualización simple es un histograma para los rendimientos diarios en el precio de las acciones de AMZN. Se utilizan las librerías matplotlib para generar histogramas y seaborn para diagramas de caja:
amzn_df["Returns"] = (amzn_df["Close"] - amzn_df["Open"])/amzn_df["Open"]
amzn_df["Returns"].hist()
plt.title("AMZN - Distribución del Rendimiento de Acciones")
plt.show()
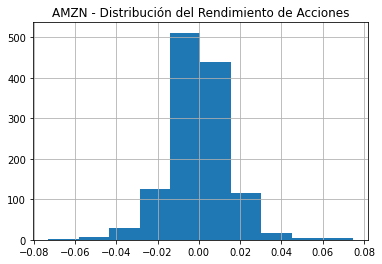
googl_df["Returns"] = (googl_df["Close"] - googl_df["Open"])/googl_df["Open"]
googl_df["Returns"].hist()
plt.title("GOOGL - Distribución del Rendimiento de Acciones")
plt.show()
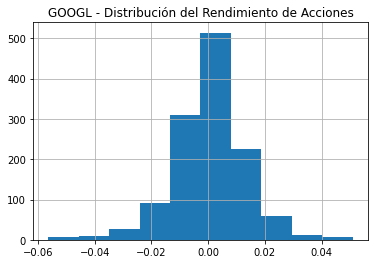
aapl_df["Returns"] = (aapl_df["Close"] - aapl_df["Open"])/aapl_df["Open"]
aapl_df["Returns"].hist()
plt.title("AAPL - Distribución del Rendimiento de Acciones")
plt.show()
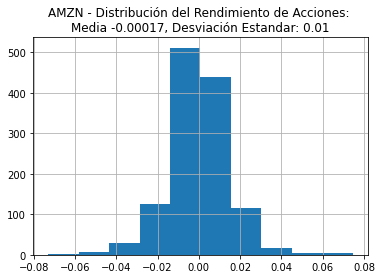
También se pueden calcular los rendimientos medios y la desviación estándar en los rendimientos de cada acción y mostrarlos en el título del histograma. Estas estadísticas son muy importantes para los inversores. Los rendimientos medios nos dan una idea de la rentabilidad de una inversión en acciones. La desviación estándar es una medida de cuánto fluctúan los rendimientos. A esto se le llama riesgo en el mundo financiero. Por lo general, los riesgos más altos están asociados con retornos más altos. A continuación un ejemplo para AMZN. Primero se almacenan la media y la desviación estándar en variables, se utiliza la cadena f para formatear el título:
mean_amnz_returns = np.round(amzn_df["Returns"].mean(), 5)
std_amnz_returns = np.round(amzn_df["Returns"].std(), 2)
amzn_df["Returns"].hist()
plt.title(f'AMZN - Distribución del Rendimiento de Acciones: \nMedia {mean_amnz_returns}, Desviación Estandar: {std_amnz_returns}')
plt.show()
Otra visualización de datos útil son los diagramas de caja. Similar a los histogramas, esta es otra forma de visualizar la media, la dispersión y la asimetría en los datos. En el contexto de los datos financieros obtenidos, se pueden comparar los rendimientos medios, la dispersión de los rendimientos y la asimetría en los rendimientos de cada acción, esto permite tomar las decisiones de inversión. Primero, se combinan los rendimientos de cada acción en un solo marco de datos:
amzn_df["Ticker"] = "AMZN"
googl_df["Ticker"] = "GOOGL"
aapl_df["Ticker"] = "AAPL"
df = pd.concat([amzn_df, googl_df, aapl_df])
df = df[["Ticker", "Returns"]]
df.head()
| Ticker | Returns | |
|---|---|---|
| 0 | AMZN | -0.009296 |
| 1 | AMZN | -0.009587 |
| 2 | AMZN | -0.001762 |
| 3 | AMZN | 0.008888 |
| 4 | AMZN | -0.008092 |
sns.boxplot(x= df["Ticker"], y = df["Retornos de Acciones"])
plt.title("Diagramas de Caja de Retornos de Acciones de: \nAMZN, GOOGL y AAPL")
plt.show()
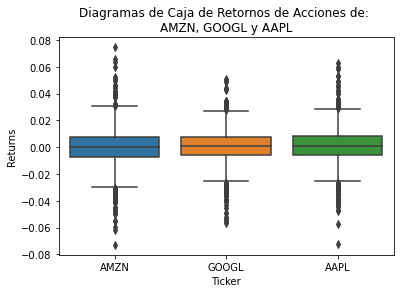
La visualización final a realizar es la correlación para los retornos. Esta visualización permite comprender si existen relaciones lineales entre los rendimientos del precio de las acciones. Esto es importante porque puede proporcionar información sobre la relación entre las acciones en la cartera de un inversor y, como resultado, también puede ayudar a informar cómo un inversor construye su cartera. Para crear el mapa de calor, primero se crea un nuevo marco de datos que contenga una columna para cada ticker:
df_corr = pd.DataFrame({"AMZN":amzn_df["Returns"], "GOOGL":googl_df["Returns"], "AAPL":aapl_df["Returns"]})
df_corr.head()
| AMZN | GOOGL | AAPL | |
|---|---|---|---|
| 0 | -0.009296 | -0.000211 | -0.009262 |
| 1 | -0.009587 | 0.000172 | -0.001549 |
| 2 | -0.001762 | 0.003953 | -0.012659 |
| 3 | 0.008888 | -0.003902 | 0.014684 |
| 4 | -0.008092 | -0.007985 | 0.000192 |
sns.heatmap(df_corr[['AMZN','GOOGL','AAPL']].corr(), annot=True, cmap = 'Blues')
plt.show()
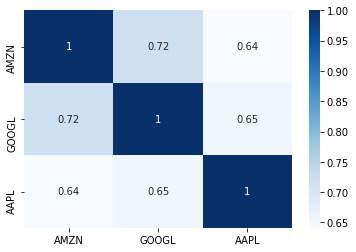
Este tipo de gráfico muestra, estas acciones tienen una relación lineal positiva. Esto significa que cuando aumentan los rendimientos diarios de AMZN, es probable que también aumenten AAPL y GOOGL. Lo contrario también es cierto. Si los retornos de AMZN disminuyen, es probable que los demás también disminuyan. Una buena cartera de inversiones contiene activos diversificados. En este contexto, esto significa que se debe seleccionar acciones que no estén fuertemente correlacionadas entre sí, como AAPL, AMZN y GOOGL. Esto se debe a que si los rendimientos de una acción caen, los rendimientos de toda su cartera también disminuirán. En una cartera diversificada con acciones que no están correlacionadas, el precio de una acción no necesariamente disminuirá o aumentará junto con los demás.
Indicadores de retraso¶
Los siguientes cálculos que se analizan son dos tipos diferentes de indicadores rezagados, la media móvil y los gráficos de la banda de Bollinger. El promedio móvil es una técnica común que utilizan los analistas para suavizar las fluctuaciones a corto plazo en los precios de las acciones para comprender las tendencias en la dirección de los precios. Aquí traza la media móvil de AMZN, GOOGL y AAPL. Comenzando con AMZN, se traza el promedio móvil de 10 días para el precio de las acciones de cierre ajustado de AMZN y se consideran los precios de las acciones después del 23 de enero de 2021:
cutoff = datetime.datetime(2021,1,23)
amzn_df["Date"] = pd.to_datetime(amzn_df["Date"], format="%Y/%m/%d")
amzn_df = amzn_df[amzn_df["Date"] > cutoff]
amzn_df["SMA_10"] = amzn_df["Close"].rolling(window=10).mean()
amzn_df.head()
| Date | High | Low | Open | Close | Volume | Adj Close | Returns | Ticker | SMA_10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1133 | 2021-01-25 | 3363.889893 | 3243.149902 | 3328.500000 | 3294.000000 | 3749800 | 3294.000000 | -0.010365 | AMZN | NaN |
| 1134 | 2021-01-26 | 3338.000000 | 3282.870117 | 3296.360107 | 3326.129883 | 2955200 | 3326.129883 | 0.009031 | AMZN | NaN |
| 1135 | 2021-01-27 | 3346.520020 | 3207.080078 | 3341.489990 | 3232.580078 | 4660200 | 3232.580078 | -0.032593 | AMZN | NaN |
| 1136 | 2021-01-28 | 3301.679932 | 3228.689941 | 3235.040039 | 3237.620117 | 3149200 | 3237.620117 | 0.000798 | AMZN | NaN |
| 1137 | 2021-01-29 | 3236.989990 | 3184.550049 | 3230.000000 | 3206.199951 | 4293600 | 3206.199951 | -0.007368 | AMZN | NaN |
plt.plot(amzn_df["Date"], amzn_df["SMA_10"])
plt.plot(amzn_df["Date"], amzn_df["Adj Close"])
plt.title("Promedio y Precio de Cierre Ajustado para AMZN")
plt.ylabel("Precio de Cierre Ajustado")
plt.xlabel("Fecha")
plt.show()
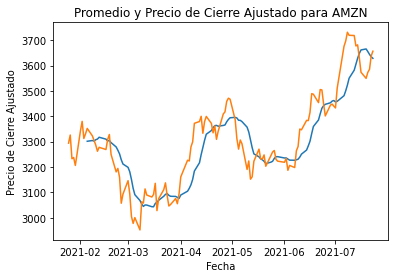
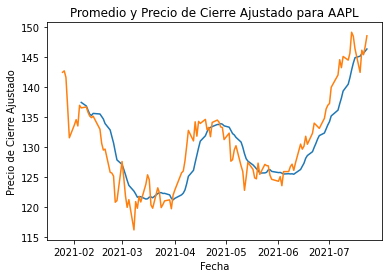
En el gráfico anterior, la línea azul muestra la media móvil y la naranja el precio de cierre ajustado. Se realizará el mismo gráfico para el resto de empresas.
googl_df["Date"] = pd.to_datetime(googl_df["Date"], format="%Y/%m/%d")
googl_df = googl_df[googl_df["Date"] > cutoff]
googl_df["SMA_10"] = googl_df["Close"].rolling(window=10).mean()
googl_df.head()
| Date | High | Low | Open | Close | Volume | Adj Close | Returns | Ticker | SMA_10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1133 | 2021-01-25 | 1921.819946 | 1859.160034 | 1912.739990 | 1894.280029 | 2529300 | 1894.280029 | -0.009651 | GOOGL | NaN |
| 1134 | 2021-01-26 | 1915.750000 | 1876.130005 | 1885.989990 | 1907.949951 | 1573100 | 1907.949951 | 0.011644 | GOOGL | NaN |
| 1135 | 2021-01-27 | 1880.469971 | 1797.280029 | 1874.910034 | 1818.939941 | 4125600 | 1818.939941 | -0.029852 | GOOGL | NaN |
| 1136 | 2021-01-28 | 1887.989990 | 1831.000000 | 1831.000000 | 1853.199951 | 2763900 | 1853.199951 | 0.012124 | GOOGL | NaN |
| 1137 | 2021-01-29 | 1847.540039 | 1801.560059 | 1834.020020 | 1827.359985 | 2226500 | 1827.359985 | -0.003631 | GOOGL | NaN |
plt.plot(googl_df["Date"], googl_df["SMA_10"])
plt.plot(googl_df["Date"], googl_df["Adj Close"])
plt.title("Promedio y Precio de Cierre Ajustado para GOOGL")
plt.ylabel("Precio de Cierre Ajustado")
plt.xlabel("Fecha")
plt.show()
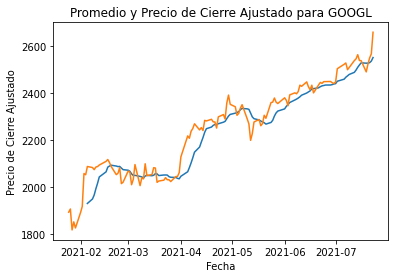
aapl_df["Date"] = pd.to_datetime(aapl_df["Date"], format="%Y/%m/%d")
aapl_df = aapl_df[aapl_df["Date"] > cutoff]
aapl_df["SMA_10"] = aapl_df["Close"].rolling(window=10).mean()
aapl_df.head()
| Date | High | Low | Open | Close | Volume | Adj Close | Returns | Ticker | SMA_10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1133 | 2021-01-25 | 145.089996 | 136.539993 | 143.070007 | 142.919998 | 157611700.0 | 142.464767 | -0.001049 | AAPL | NaN |
| 1134 | 2021-01-26 | 144.300003 | 141.369995 | 143.600006 | 143.160004 | 98390600.0 | 142.704010 | -0.003064 | AAPL | NaN |
| 1135 | 2021-01-27 | 144.300003 | 140.410004 | 143.429993 | 142.059998 | 140843800.0 | 141.607513 | -0.009552 | AAPL | NaN |
| 1136 | 2021-01-28 | 141.990005 | 136.699997 | 139.520004 | 137.089996 | 142621100.0 | 136.653336 | -0.017417 | AAPL | NaN |
| 1137 | 2021-01-29 | 136.740005 | 130.210007 | 135.830002 | 131.960007 | 177523800.0 | 131.539673 | -0.028491 | AAPL | NaN |
plt.plot(aapl_df["Date"], aapl_df["SMA_10"])
plt.plot(aapl_df["Date"], aapl_df["Adj Close"])
plt.title("Promedio y Precio de Cierre Ajustado para AAPL")
plt.ylabel("Precio de Cierre Ajustado")
plt.xlabel("Fecha")
plt.show()
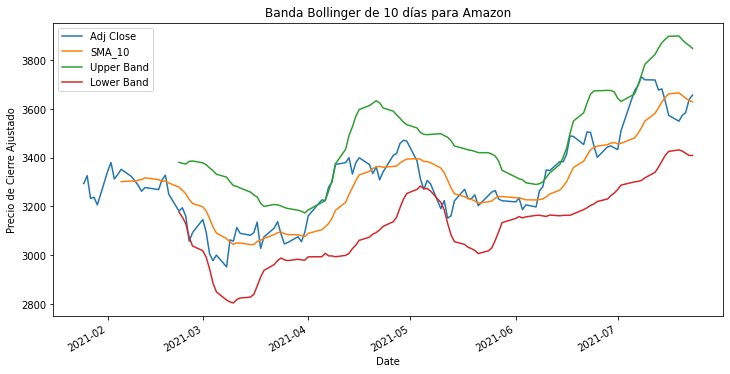
El último tipo de gráfico a utilizar, es el gráfico de la Banda de Bollinger, este es una forma de visualizar la dispersión en la media móvil. Las bandas están definidas por límites superior e inferior que están a dos desviaciones estándar de la media móvil simple. Esto es útil para los comerciantes porque permite aprovechar las fluctuaciones en la volatilidad de los precios. Se procede a generar un gráfico de banda de Bollinger para AMZN:
amzn_df["SMA_10_STD"] = amzn_df["Adj Close"].rolling(window=20).std()
amzn_df["Upper Band"] = amzn_df["SMA_10"] + (amzn_df["SMA_10_STD"] * 2)
amzn_df["Lower Band"] = amzn_df["SMA_10"] - (amzn_df["SMA_10_STD"] * 2)
amzn_df.index = amzn_df["Date"]
amzn_df[["Adj Close", "SMA_10", "Upper Band", "Lower Band"]].plot(figsize=(12,6))
plt.title("Banda Bollinger de 10 días para Amazon")
plt.ylabel("Precio de Cierre Ajustado")
plt.show()
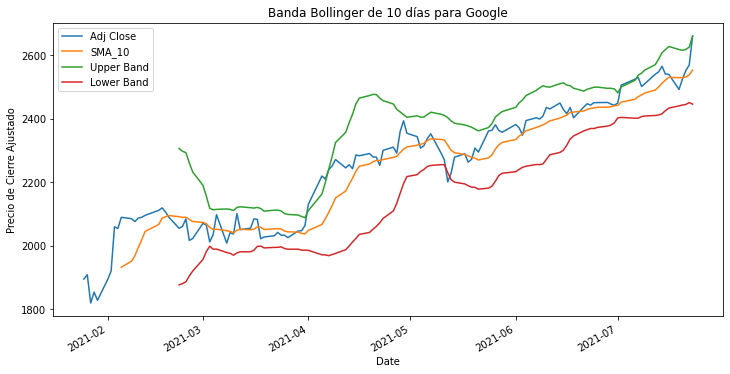
googl_df["SMA_10_STD"] = googl_df["Adj Close"].rolling(window=20).std()
googl_df["Upper Band"] = googl_df["SMA_10"] + (googl_df["SMA_10_STD"] * 2)
googl_df["Lower Band"] = googl_df["SMA_10"] - (googl_df["SMA_10_STD"] * 2)
googl_df.index = googl_df["Date"]
googl_df[["Adj Close", "SMA_10", "Upper Band", "Lower Band"]].plot(figsize=(12,6))
plt.title("Banda Bollinger de 10 días para Google")
plt.ylabel("Precio de Cierre Ajustado")
plt.show()
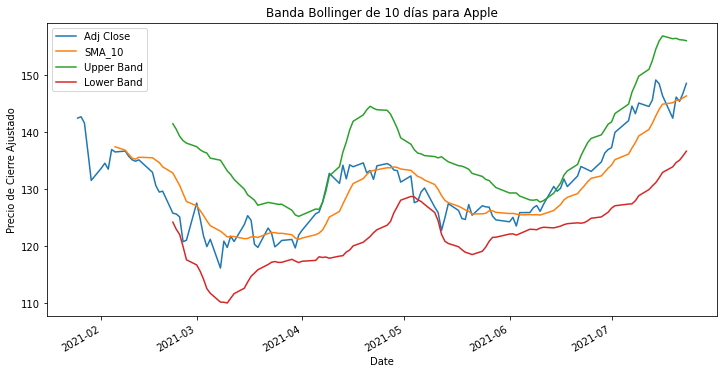
aapl_df["SMA_10_STD"] = aapl_df["Adj Close"].rolling(window=20).std()
aapl_df["Upper Band"] = aapl_df["SMA_10"] + (aapl_df["SMA_10_STD"] * 2)
aapl_df["Lower Band"] = aapl_df["SMA_10"] - (aapl_df["SMA_10_STD"] * 2)
aapl_df.index = aapl_df["Date"]
aapl_df[["Adj Close", "SMA_10", "Upper Band", "Lower Band"]].plot(figsize=(12,6))
plt.title("Banda Bollinger de 10 días para Apple")
plt.ylabel("Precio de Cierre Ajustado")
plt.show()
Existen una amplia variedad de herramientas útiles para extraer, analizar y generar información a partir de datos financieros. La combinación de estas herramientas facilita a los principiantes comenzar a trabajar con datos financieros en Python. Estas habilidades se pueden utilizar para inversiones personales, operaciones algorítmicas, creación de carteras y más. Poder generar rápidamente conocimientos estadísticos, visualizar relaciones e identificar tendencias en datos financieros es invaluable para cualquier analista o científico de datos interesado en las finanzas.