Agrupación Jerárquica: Aprendizaje Automático No Supervisado.
05 de Diciembre del 2020 - Jhonatan Montilla
Otro método popular de agrupamiento es la agrupación jerárquica. Hemos visto que en la agrupación K-Means es necesario indicar el número de agrupaciones. La agrupación jerárquica no requiere de esto. La agrupación jerárquica nos presenta algunas filas largas que forman grupos entre sí. En la agrupación jerárquica, su representación gráfica se denomina dendrograma.
La agrupación jerárquica se divide en dos tipos, aglomerativa y divisiva. La explicación detallada y sus resultados se muestran a continuación.
Divisiva: En este tipo, el conjunto de datos completo es un solo grupo. Luego, ese grupo se desglosa continuamente hasta que cada punto de datos se convierte en un grupo separado. Funciona siguiendo el método de arriba hacia abajo.
Aglomerativa: Es exactamente lo opuesto a la agrupación Divisiva, también llamado método de abajo hacia arriba. En este tipo, cada punto de datos se trata inicialmente como un grupo separado. Luego, sobre la base de la distancia de estos grupos, se forman pequeños grupos con ellos, por lo que estos pequeños grupos vuelven a formar grandes grupos.
La agrupación aglomerativa se puede realizar de varias maneras, para ilustrar, distancia completa, distancia simple, distancia promedio, enlace centroide y método de palabras. Veamos la explicación de este enfoque:
-
Distancia completa: los grupos se forman entre puntos de datos en función de las distancias máxima o más larga.
-
Distancia única: los clústeres se forman en función de la distancia mínima o más corta entre puntos de datos.
-
Distancia promedio: los grupos se forman sobre la base de la distancia mínima o más corta entre los puntos de datos.
-
Distancia del centroide: los grupos se forman en función de los centros de los grupos o la distancia del centroide.
-
Método de palabras: los grupos de clústeres se forman en función de las variantes mínimas dentro de diferentes clústeres.
Aplicación en la vida real de Agrupación Jerárquica en clústeres:
- Clasificar animales y plantas basándose en secuencias de ADN.
- Epidemias provocadas por diversos virus.
Se implementará la agrupación jerárquica en clústeres sobre los datos de mayoristas superiores que se pueden encontrar en Kaggle.com: https://www.kaggle.com/binovi/wholesale-customers-data-set
- El primer paso es importar las librerías:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import seaborn as sns
from sklearn.preprocessing import normalize
import scipy.cluster.hierarchy as shc
from sklearn.cluster import AgglomerativeClustering
df = pd.read_csv('Wholesale_customers_data.csv')
df.head()
| Channel | Region | Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicassen | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 12669 | 9656 | 7561 | 214 | 2674 | 1338 |
| 1 | 2 | 3 | 7057 | 9810 | 9568 | 1762 | 3293 | 1776 |
| 2 | 2 | 3 | 6353 | 8808 | 7684 | 2405 | 3516 | 7844 |
| 3 | 1 | 3 | 13265 | 1196 | 4221 | 6404 | 507 | 1788 |
| 4 | 2 | 3 | 22615 | 5410 | 7198 | 3915 | 1777 | 5185 |
Se debe normalizar todo el conjunto de datos para facilitar la agrupación.
data_scaled = normalize(df)
data_scaled = pd.DataFrame(data_scaled, columns=df.columns)
data_scaled.head()
| Channel | Region | Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicassen | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.000112 | 0.000168 | 0.708333 | 0.539874 | 0.422741 | 0.011965 | 0.149505 | 0.074809 |
| 1 | 0.000125 | 0.000188 | 0.442198 | 0.614704 | 0.599540 | 0.110409 | 0.206342 | 0.111286 |
| 2 | 0.000125 | 0.000187 | 0.396552 | 0.549792 | 0.479632 | 0.150119 | 0.219467 | 0.489619 |
| 3 | 0.000065 | 0.000194 | 0.856837 | 0.077254 | 0.272650 | 0.413659 | 0.032749 | 0.115494 |
| 4 | 0.000079 | 0.000119 | 0.895416 | 0.214203 | 0.284997 | 0.155010 | 0.070358 | 0.205294 |
La creación de un dendrograma de un conjunto de datos normalizado creará un gráfico como el que se muestra a continuación, se creará un dendrograma utilizando el método Word Linkage, también es posible crear dendrogramas de otro tipo si se requiere a partir de este dendrograma, se entiende que los puntos de datos primero están formando pequeños grupos, luego estos pequeños grupos se convierten gradualmente en grupos más grandes.
plt.figure(figsize=(10, 7))
plt.title("Dendrogramas usando Ward")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
plt.show()
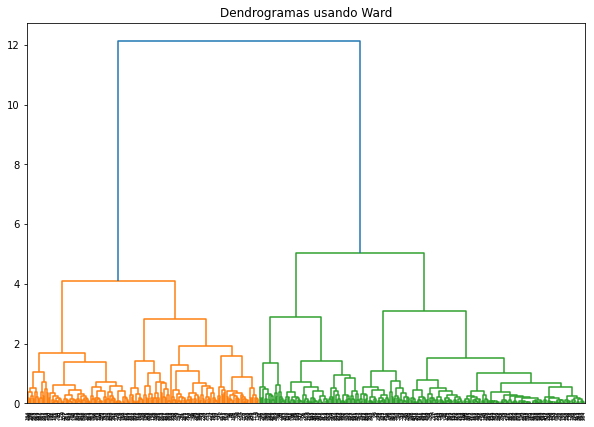
Al observar el dendrograma, se pueden ver que los grupos más pequeños están formando grupos más grandes gradualmente. Se dan los puntos de datos en el eje X y la distancia del grupo en el eje Y. La distancia máxima para los dos grupos más grandes formados por la línea azul es 7 (no se han formado nuevos grupos desde entonces y la distancia no ha aumentado). Se traza una línea para esta distancia para la conveniencia de nuestra comprensión. Hagamos el dendrograma usando otro enfoque que es Enlace completo:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms using Complete")
dend1 = shc.dendrogram(shc.linkage(data_scaled, method='complete'))
plt.show()
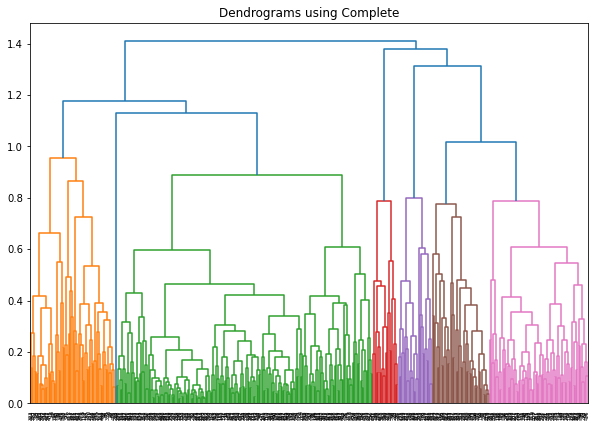
Se crearán dendrogramas utilizando un enlace único:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms using Single")
dend2 = shc.dendrogram(shc.linkage(data_scaled, method='single'))
plt.show()
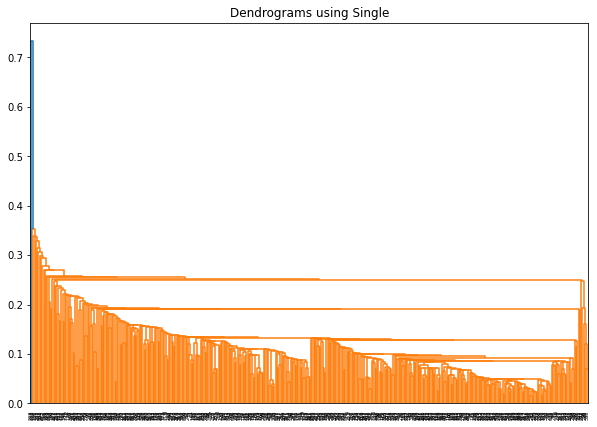
Ahora utilizando el Promedio:
plt.figure(figsize=(10, 7))
plt.title("Dendrogramas usando Promedio")
dend3 = shc.dendrogram(shc.linkage(data_scaled, method='average'))
plt.show()
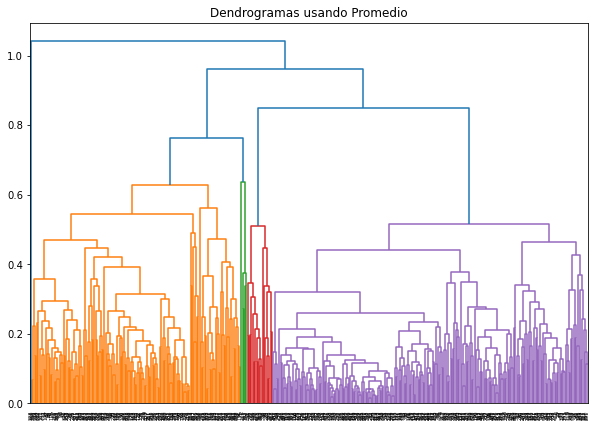
Ahora se observa el grupo por valor medio a manera de entender qué tipo de productos se venden en promedio y en cual grupo.
agg_wholwsales = df.groupby(['Region','Channel']).mean()
agg_wholwsales
| Fresh | Milk | Grocery | Frozen | Detergents_Paper | Delicassen | ||
|---|---|---|---|---|---|---|---|
| Region | Channel | ||||||
| 1 | 1 | 12902.254237 | 3870.203390 | 4026.135593 | 3127.322034 | 950.525424 | 1197.152542 |
| 2 | 5200.000000 | 10784.000000 | 18471.944444 | 2584.111111 | 8225.277778 | 1871.944444 | |
| 2 | 1 | 11650.535714 | 2304.250000 | 4395.500000 | 5745.035714 | 482.714286 | 1105.892857 |
| 2 | 7289.789474 | 9190.789474 | 16326.315789 | 1540.578947 | 8410.263158 | 1239.000000 | |
| 3 | 1 | 13878.052133 | 3486.981043 | 3886.734597 | 3656.900474 | 786.682464 | 1518.284360 |
| 2 | 9831.504762 | 10981.009524 | 15953.809524 | 1513.200000 | 6899.238095 | 1826.209524 |
Para concluir, en este artículo se ilustró la agrupación jerárquica y los diferentes tipos de dendrogramas implementados sobre el conjunto de datos de mayoristas, también se pudieron observar los dendrogramas de distintos tipos, como Enlace completo, Enlace único, Enlace promedio y Método de palabras.