Análisis Exploratorio de Datos (Exploratory Data Analysis, EDA).
Publicado el: 25 de Noviembre del 2020 - Jhonatan Montilla
El análisis exploratorio de datos permite entender mejor los datos proporcionados para que poder encontrar algo de sentido en estos. En estadística, el análisis de datos exploratorios es un enfoque para analizar conjuntos de datos para resumir sus características principales, a menudo con métodos visuales, se puede utilizar o no un modelo estadístico, sin embargo, el EDA se utiliza principalmente para observar lo que los datos pueden decirnos más allá del modelo formal o la prueba de hipótesis.
Un EDA desarrollado en Python utiliza la visualización de datos para representar gráficamente patrones y conocimientos significativos, también implica la preparación de conjuntos de datos para su análisis, eliminando irregularidades en estos.
A través del EDA, las empresas pueden tomar decisiones comerciales que pueden traer consecuencias si no se realiza correctamente, puede obstaculizar pasos adicionales en el proceso de construcción del modelo de aprendizaje automático, si se hace bien, puede mejorar la eficacia de todo lo que se haga a continuación.
Revisarán los siguientes temas con respecto a los datos: Suministro, Limpieza, Análisis univariado, Análisis bivariado, y Analisis multivariable.
1. El Origen de los datos.
El suministro de datos es el proceso de buscar y cargar los datos en nuestro sistema, en general, hay dos formas en las que podemos encontrar datos, datos privados, y datos públicos,
-
Los datos privados: Como sugiere su nombre, son proporcionados por organizaciones privadas, existen muchas preocupaciones por la seguridad y la privacidad asociadas a estos datos, este tipo de datos se utiliza principalmente para análisis interno de las organizaciones.
-
Los datos públicos: Este tipo de datos está disponible para todos, podemos encontrarlos en sitios web gubernamentales, de organizaciones públicas, etc. Cualquiera puede acceder a estos datos, es decir, no necesitamos ningún permiso o aprobación especial.
El primer paso del EDA es el suministro de datos, hemos visto cómo podemos acceder a los datos para cargarlos en nuestro sistema. Ahora, el siguiente paso es limpiarlos.
2. Limpieza de datos.
Es muy importante deshacerse de las irregularidades, realizar una limpieza de datos después de introducirlos en nuestro sistema, las irregularidades son de diferentes tipos: Valores faltantes, formato incorrecto, encabezados incorrectos, y valores anómalos ó atípicos.
Primeramente, se importan las bibliotecas necesarias y se almacenan los datos en el sistema para su análisis.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv ('marketing_analysis.csv', sep=';',low_memory=False)
data.head(5)
| banking marketing | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | Unnamed: 12 | Unnamed: 13 | Unnamed: 14 | Unnamed: 15 | Unnamed: 16 | Unnamed: 17 | Unnamed: 18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | customer id and age. | NaN | Customer salary and balance. | NaN | Customer marital status and job with education... | NaN | particular customer before targeted or not | NaN | Loan types: loans or housing loans | NaN | Contact type | NaN | month of contact | duration of call | NaN | NaN | NaN | outcome of previous contact | response of customer after call happned |
| 1 | customerid | age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response |
| 2 | 1 | 58 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no |
| 3 | 2 | 44 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no |
| 4 | 3 | 33 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no |
Observando el conjunto de datos, existen algunas discrepancias en el encabezado de las columnas en las dos primeras filas, los datos correctos son del número de índice, por lo tanto, se deben ajustar las dos primeras filas, en este caso se eliminarán dichas filas, para que el conjunto de datos tenga sentido se cargarán los datos nuevamente sin incluir las dos primeras filas, como se muestra a continuación.
data = pd.read_csv('marketing_analysis.csv', sep=';', skiprows = 2) # Eliminan las dos primeras filas.
data.head(5) # Muestra las cinco primeras filas
| customerid | age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 58.0 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no |
| 1 | 2 | 44.0 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no |
| 2 | 3 | 33.0 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no |
| 3 | 4 | 47.0 | 20000 | 1506 | married | blue-collar,unknown | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no |
| 4 | 5 | 33.0 | 0 | 1 | single | unknown,unknown | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no |
Dentro de un conjunto de datos se pueden fusionar diferentes columnas para obtener mejor comprensión de los datos, de manera similar, se puede dividir una columna en varias columnas según los requerimientos o necesidad de comprensión, agregarle nombres, es muy importante que todas las columnas tengan nombres en el conjunto de datos. Observando el conjunto de datos anterior, la columna "customerid" no tiene importancia para nuestro análisis, así como también, la columna "jobedu", que contienen la información de trabajo y educación, por lo que se procederá a eliminar la columna "customerid" y dividir la columna "jobedu" en dos columnas, trabajo y educación, posteriormente también será eliminada.
data.drop('customerid', axis = 1, inplace = True) # Elimina la variable "customerid".
# Se extraen los valores trabajo y educación de la variable "jobedu" y se crean dos variables con sus respectivos nombres.
data['job']= data["jobedu"].apply(lambda x: x.split(",")[0]) # Se crea la columna empleo
data['education']= data["jobedu"].apply(lambda x: x.split(",")[1]) # Se crea la columna educación
data.drop('jobedu', axis = 1, inplace = True) # Elimina del dataframe la columna "jobedu"
data.head(5)
| age | salary | balance | marital | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | job | education | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58.0 | 100000 | 2143 | married | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no | management | tertiary |
| 1 | 44.0 | 60000 | 29 | single | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no | technician | secondary |
| 2 | 33.0 | 120000 | 2 | married | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no | entrepreneur | secondary |
| 3 | 47.0 | 20000 | 1506 | married | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no | blue-collar | unknown |
| 4 | 33.0 | 0 | 1 | single | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no | unknown | unknown |
Valores faltantes.¶
Si existen valores faltantes ó perdidos en el conjunto de datos, antes de realizar cualquier análisis estadístico, se deben procesar adecuadamente. Existen principalmente tres tipos de valores perdidos.
- M C A R, (Faltan completamente al azar): Estos valores no dependen de ninguna otra característica.
- M A R, (Faltan al azar): Estos valores pueden depender de algunas otras características.
- M N A R, (Faltan no aleatoriamente): Estos valores perdidos tienen alguna razón por la que faltan.
Se procede a revisar cuales columnas tienen valores faltantes en el conjunto de datos.
data.isnull().sum() # Suma la cantidad de valores faltantes.
age 20 salary 0 balance 0 marital 0 targeted 0 default 0 housing 0 loan 0 contact 0 day 0 month 50 duration 0 campaign 0 pdays 0 previous 0 poutcome 0 response 30 job 0 education 0 dtype: int64
Como se puede observar, tres columnas contienen valores faltantes. Los valores faltantes se pueden manejar descartando los registros perdidos o imputando los valores por el promedio de los datos existentes.
Tratamiento de valores faltantes.
Se procederá a tratar los valores faltantes de la columna de edad, y se procede nuevamente a comprobar los valores que faltan en el conjunto de datos.
data = data[~data.age.isnull()].copy() # Elimina los registros faltantes de la variable edad.
data.isnull().sum() # Suma nuevamente la cantidad de valores faltantes.
age 0 salary 0 balance 0 marital 0 targeted 0 default 0 housing 0 loan 0 contact 0 day 0 month 50 duration 0 campaign 0 pdays 0 previous 0 poutcome 0 response 30 job 0 education 0 dtype: int64
Para la administración valores perdidos de la variable del mes, dado que dicha variable es de tipo objeto, primero se calcula la moda de esta, para luego imputar los valores faltantes con ese valor.
month_mode = data.month.mode()[0] # Calcula la moda de la variable mes.
data.month.fillna(month_mode, inplace = True) # Se imputan los valores faltantes con la moda de la variable mes.
data.month.isnull().sum() # Se suman los valores faltantes en la variable mes.
0
Administración de valores faltantes en la columna respuesta, debido que esta es la variable objetivo, al imputar los valores faltante podría afectar significativamente el análisis, por lo tanto, lo más conveninete en este caso es eliminar todos los valores faltantes de dicha la columna.
data = data[~data.response.isnull()].copy() # Elimina registros faltantes en la columna respuesta.
Se procede a comprobar si los valores faltantes en todo el conjunto de datos se han eliminado correctamente,
data.isnull().sum() # Sumatoria de valores faltantes presentes en el dataset.
age 0 salary 0 balance 0 marital 0 targeted 0 default 0 housing 0 loan 0 contact 0 day 0 month 0 duration 0 campaign 0 pdays 0 previous 0 poutcome 0 response 0 job 0 education 0 dtype: int64
También será necesario completar valores faltantes como, "NaN" para que al realizar cualquier análisis estadístico no se afecte su resultado.
Manejo de valores atípicos.¶
Ahora será necesario manejar los valores atípicos del conjunto de datos.
Los valores atípicos son valores que están mucho más allá de los puntos de datos más cercanos, hay dos tipos de valores atípicos:
-
Valores atípicos univariados: los valores atípicos univariados, son puntos de datos cuyos valores se encuentran más allá del rango de valores esperados basados en una variable.
-
Valores atípicos multivariados: Algunos datos en una variable cuando se grafican muestran ciertos valores que no están más allá del rango esperado, pero cuando se grafican en conjunto con alguna otra variable, estos valores pueden estar muy lejos del valor esperado.
Entonces, después de comprender las causas de estos valores atípicos, se pueden manejar eliminandolos, imputandolos ó dejándolos como están si esto tiene más sentido.
Normalización de valores.¶
Para realizar análisis de datos en un conjunto de valores, se debe asegurar que los valores en la misma columna estén en la misma escala. Por ejemplo, si los datos contienen los valores de la velocidad máxima de los automóviles de diferentes empresas, entonces toda la columna debe estar en una escala de metros sobre segundos, ó en una escala de millas sobre segundos.
Ahora que tenemos claro cómo obtener y limpiar los datos, veamos cómo podemos analizarlos.
- Análisis Univariante: Cuando se analizan los datos sobre una sola variable del conjunto de datos.
- Análisis Univariante Categórico no Ordenado: Una variable desordenada es una variable categórica que no tiene un orden definido, tomando como ejemplo los datos de la columna trabajo del conjunto de datos, estos se divide en muchas subcategorías como, técnico, obrero, servicios, administración, etc. Es decir, no se le asigna peso ni medida a ningún valor.
Ahora, analizando la categorías de trabajo utilizando gráficos, dado que la variable Job es una categoría, se utiliza un diagrama de barras.
data.job.value_counts(normalize=True) # Cuantifica los valores normalizados de las categorías de la variable "job".
blue-collar 0.215274 management 0.209273 technician 0.168043 admin. 0.114369 services 0.091849 retired 0.050087 self-employed 0.034853 entrepreneur 0.032860 unemployed 0.028830 housemaid 0.027413 student 0.020770 unknown 0.006377 Name: job, dtype: float64
data.job.value_counts(normalize=True).plot.barh()# Gráfico de categorías en la variable "job".
plt.show()
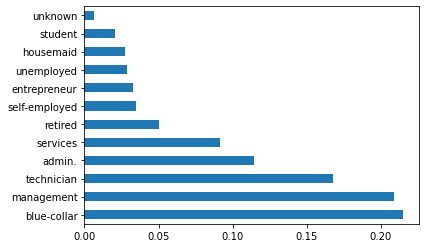
En el diagrama de barras anterior, se puede inferir que el conjunto de datos contiene más cantidad de trabajadores manuales que en comparación con las otras categorías.
- Análisis Univariante Categórico Ordenado: Las variables ordenadas son aquellas variables que tienen un rango de orden natural, algunos ejemplos de variables ordenadas categóricamente en el conjunto de datos son: Enero, Febrero, Marzo, es decir, meses. También, primaria, secundaria, es decir, educación.
Ahora, se procede a analizar la variable educación del conjunto de datos a través de un gráfico circular.
data.education.value_counts(normalize=True) # Cuantifica los valores normalizados de las categorías de la variable "education".
secondary 0.513275 tertiary 0.294192 primary 0.151436 unknown 0.041097 Name: education, dtype: float64
data.education.value_counts(normalize=True).plot.pie() # Gráfico de las categorías de la variable "education".
plt.show()
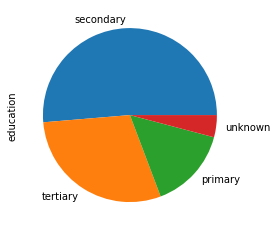
Según el gráfico anterior, se puede inferir que el conjunto de datos tiene un gran número de ellos que pertenecen a la educación secundaria, después, educación terciaria y por último primaria. Además, se desconoce un porcentaje muy pequeño de ellos. Así es como se realiza un análisis categórico univariante, si la variable es numérica, se analiza calculando su media, mediana, desviación estándar, etc. Estos valores se obtienen utilizando la función "describe".
data.salary.describe() # Datos estadísticos de la variable "salary".
count 45161.000000 mean 57004.849317 std 32087.698810 min 0.000000 25% 20000.000000 50% 60000.000000 75% 70000.000000 max 120000.000000 Name: salary, dtype: float64
- Análisis Bivariado: Consiste en analizar los datos teniendo en cuenta dos variables de un conjunto de datos.
- Análisis Numérico-Numérico: Cuando se realiza para dos o más variables numéricas, este se realiza de tres maneras distintas: Gráfico de Dispersión, Gráfico de Sectores, y Matriz de Correlación.
Gráficos de dispersión.
Tomando las variables del conjunto de datos, "Saldo" y "Salario", se obtiene.
plt.scatter(data.salary,data.balance) # Diagrama de puntos de las variables "balance" y "salary".
plt.show()
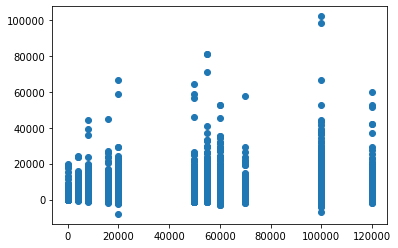
Tomando las variables del conjunto de datos, "Saldo" y "Edad", se obtiene.
data.plot.scatter(x="age",y="balance") # Diagrama de dispersión de las variables "age" y "balance".
plt.show()
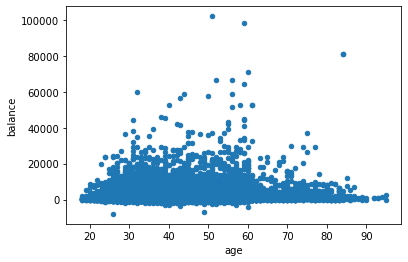
Tomando las variables del conjunto de datos, "Saldo", "Salario" y "Edad", utilizando la biblioteca Seaborn se obtiene.
sns.pairplot(data = data, vars=['salary','balance','age'])# Diagramas combinados de las variables "salary", "balance" y "age".
plt.show()
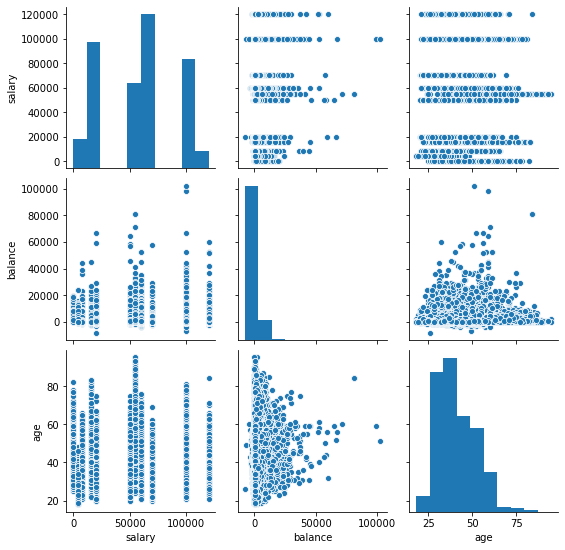
Matriz de correlación,¶
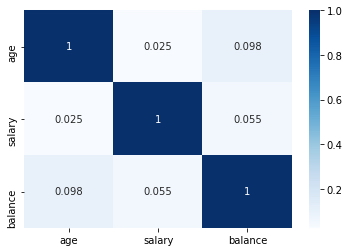
Dado que no se pueden utilizar más de dos variables en los ejes, x e y, en los diagramas de dispersión, es difícil observar la relación entre tres variables numéricas en un solo gráfico, en este caso, se utiliza una matriz de correlación, primero se crea una matriz empleando "edad", "salario" y "balance", después se utiliza un mapa de gradientes de la biblioteca Seaborn con la matriz.
data[['age','salary','balance']].corr() # Matriz de correlación, variables: "age", "salary", y "balance".
| age | salary | balance | |
|---|---|---|---|
| age | 1.000000 | 0.024513 | 0.097710 |
| salary | 0.024513 | 1.000000 | 0.055489 |
| balance | 0.097710 | 0.055489 | 1.000000 |
sns.heatmap(data[['age','salary','balance']].corr(), annot=True, cmap = 'Blues') # Grafica de matriz de correlación, variables: "age", "salary", y "balance".
plt.show()
- Análisis Numérico-Categórico: Es el análisis que se realiza entre una variable numérica y una categórica de un conjunto de datos, este se realiza principalmente mediante diagramas de caja, a través de la media, y la mediana.
Se toman las variables "salary" y "response" del conjunto de datos, para obtener la media y la mediana usando "groupby".
Cálculo de la media:
data.groupby('response')['salary'].mean() # Media de la variable "salary" agrupado por la variable "response".
response no 56769.510482 yes 58780.510880 Name: salary, dtype: float64
Se observa que no existe una diferencia significativa entre las respuestas de "Sí" y "No" según el salario.
Calculo de la mediana:
data.groupby('response')['salary'].median() # Mediana de la variable "salary" agrupado por la variable "response".
response no 60000 yes 60000 Name: salary, dtype: int64
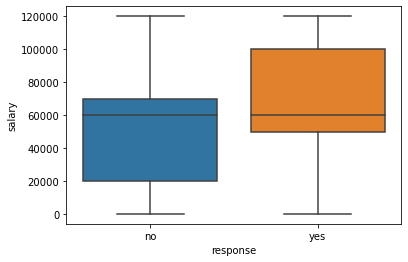
Observando la media y la mediana se podría concluir que las respuestas de "Sí" y "No", permanecen igual independientemente del salario de la persona, pero, ¿es realmente cierto esto?, para responder a esta pregunta será necesario realizar undiagrama de caja, para verificar su comportamiento de manera gráfica.
sns.boxplot(data.response, data.salary) # Gráfico de cajas para de la variable "salary" con respuestas "Si" y "No".
plt.show()
Se puede observar dos imágenes muy diferentes en los diagramas de caja de la media y la mediana. El rango intercuartílico (IQR), para los clientes que dieron una respuesta positiva se encuentra en el lado del salario más alto.
- Análisis Categórico-Categórico.
Dado que la variable objetivo del estudio es la tasa de respuesta, se deberá observar su comportamiento con respecto al resto de variables, educación, estado civil, etc. Para esto en lugar de permanecer como "Sí" y "No", será necesario convertirla a binario, es decir, en ceros y unos para obtener una “Tasa de respuestas”, por lo que crearemos una nueva variable llamada con ese nombre (response_rate).
data['response_rate'] = np.where(data.response=='yes',1,0) # Total de respuestas "sí" = 1, "no" = 0.
data.response_rate.value_counts()
0 39876 1 5285 Name: response_rate, dtype: int64
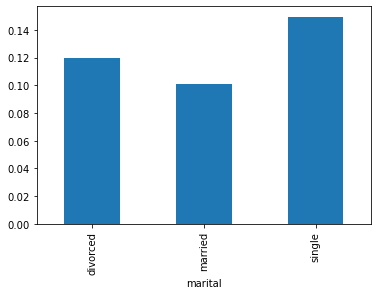
data.groupby('marital')['response_rate'].mean().plot.bar() # Gráfico de la variable "marital" con respecto al valor promedio de la variable "response_rate".
plt.show()
A través del gráfico anterior, se puede inferir que la respuesta positiva se obtiene en mayor número de los individuos solteros, de manera similar, se puede trazar los gráficos para la tasa de préstamo frente a la tasa de respuesta, préstamos para vivienda frente a tasa de respuesta, etc.
- Análisis multivariado: Es el análisis de los datos considerando más de dos variables de un conjunto de datos.
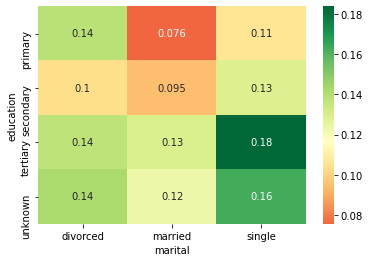
Se pretende observar cómo 'Educación', 'Marital' y ' Tasa de respuesta ' varían entre sí, primero, será necesario crear una tabla dinámica con las tres variables y luego crearemos un mapa de gradientes (heat map).
edu_mar = pd.pivot_table(data=data, index='education', columns='marital',values='response_rate') # Tabla dinámica de las variables "education", "marital", con respecto a "response_rate".
print(edu_mar)
marital divorced married single education primary 0.138852 0.075601 0.106808 secondary 0.103559 0.094650 0.129271 tertiary 0.137415 0.129835 0.183737 unknown 0.142012 0.122519 0.162879
sns.heatmap(edu_mar, annot=True, cmap = 'RdYlGn', center=0.117) # Mapa de gradientes de la tabla dinámica.
plt.show()
Observando en el mapa de gradientes, se puede inferir que las personas casadas con educación primaria tienen menos probabilidades de responder positivamente a la encuesta y las personas solteras con educación terciaria tienen más probabilidades de responder positivamente a la encuesta.
De manera similar, se pueden trazar los mapas de gradientes con respecto a "response_rate" para las variables "trabajo" vs "matrimonio", "educación" vs "poutcome",etc.
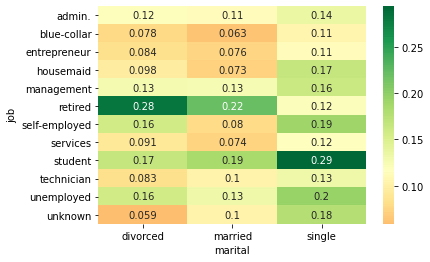
job_mar = pd.pivot_table(data=data, index='job', columns='marital',values='response_rate') # Tabla dinámica("job", "marital", "response_rate").
sns.heatmap(job_mar, annot=True, cmap = 'RdYlGn', center=0.117) # Mapa de gradientes.
plt.show()
Con este gráfico se puede inferir que las personas divorciadas con trabajo desconocido tienen menos probabilidades de responder positivamente a la encuesta y las personas solteras con trabajo de estudiante tienen más probabilidades de responder positivamente.
edu_pou = pd.pivot_table(data=data, index='education', columns='poutcome',values='response_rate') # Tabla dinámica("marital", "education", "response_rate").
sns.heatmap(edu_pou, annot=True, cmap = 'RdYlGn', center=0.117) # Mapa de gradientes.
plt.show()
Con este gráfico se puede inferir que las personas divorciadas con ingresos desconocidos tienen menos probabilidades de responder positivamente a la encuesta y las personas con ingresos y educación desconocido tienen más probabilidades de responder positivamente la encuesta.
Conclusiones.¶
Un análisis exploratorio de datos permite observar más allá de los datos, cuanto más se exploran los datos, más información se extrae de ellos, como analista de datos, aproximadamente el 80% del tiempo debe ser dedicado a comprender los datos para resolver problemas comerciales a través del EDA.