Función groupby() de Pandas.
Publicado el: 15 de Diciembre del 2020 - Jhonatan Montilla
Una función para resumen y análisis de datos.
Groupby es una función muy popular en Pandas. Es especialmente buena para resumir, transformar, filtrar y en algunas ocasiones para el análisis de datos muy esenciales. En este artículo, se explicará el uso de la función groupby() en detalle con un ejemplo.
Carga de Librerías
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
Carga del conjunto de datos.
Para este artículo, se utilizará un conjunto de datos llamado "Rendimiento de estudiantes" disponible en Kaggle, sin embargo para su descarga de manera más expedita puede hacer clic en el enlace a nuestro repositorio.
df = pd.read_csv('students_performance.csv')
df.head()
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | |
|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 |
| 1 | female | group C | some college | standard | completed | 69 | 90 | 88 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 |
| 3 | male | group A | associate's degree | free/reduced | none | 47 | 57 | 44 |
| 4 | male | group C | some college | standard | none | 76 | 78 | 75 |
- Se realizarán algunos ejercicios para ejemplificar de manera más larga lo que se puede hacer con la función groupby() de Pandas. Primeraente se creará un nuevo conjunto de datos más pequeño de dos columnas, las columnas son "género" y "puntuación de lectura".
test = df[['gender', 'reading score']]
test.head()
| gender | reading score | |
|---|---|---|
| 0 | female | 72 |
| 1 | female | 90 |
| 2 | female | 95 |
| 3 | male | 57 |
| 4 | male | 78 |
- Posteriormente, se procederá a mostrar el puntaje de lectura por cada uno de los géneros, en este caso para femenino.
female = test['gender'] == 'female'
test[female].head()
| gender | reading score | |
|---|---|---|
| 0 | female | 72 |
| 1 | female | 90 |
| 2 | female | 95 |
| 5 | female | 83 |
| 6 | female | 95 |
- De la misma manera, se muestran los datos para el género masculino
male = test['gender'] == 'male'
test[male].head()
| gender | reading score | |
|---|---|---|
| 3 | male | 57 |
| 4 | male | 78 |
| 7 | male | 43 |
| 8 | male | 64 |
| 10 | male | 54 |
- Ahora, haciendo uso de los dos conjuntos de datos de damas y caballeros anteriores, se calculará la puntuación promedio de lectura para ambos géneros de manera independiente.
fe_avg = test[female]['reading score'].mean()
male_avg = test[male]['reading score'].mean()
print("Femenino: ", fe_avg, "Masculino: ", male_avg)
Femenino: 72.60810810810811 Masculino: 65.47302904564316
-
La puntuación media de lectura de las damas es 72,61 y la puntuación media de lectura de los caballeros es 65,47.
-
Ahora, se creará un DataFrame con la puntuación promedio de lectura de mujeres y hombres juntos.
df_reading = pd.DataFrame({'Gender': ['female', 'male'], 'reading score': [fe_avg, male_avg]})
df_reading.head()
| Gender | reading score | |
|---|---|---|
| 0 | female | 72.608108 |
| 1 | male | 65.473029 |
¿Cómo funciona groupby()?
La función groupby() divide el conjunto de datos según los criterios que se requieran. Ahora se mostrarán los datos de la misma manera pero más eficiente en cuanto a código a través de la función groupby(), en donde se dividiran los datos en función del género y se aplicará la el promedio directamente con una simple línea de código:
test.groupby('gender').mean()
| reading score | |
|---|---|
| gender | |
| female | 72.608108 |
| male | 65.473029 |
Como se puede observar, a través de este pequeño fragmento de código se obtiene el mismo resultado.
Grupos con groupby()
Haciendo uso del conjunto de datos original "df", se realizarán varios grupos, el primero con la etnia.
race = df.groupby('race/ethnicity')
print(race)
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000201AA804C88>
- Este código devuelve un objeto.
- Se proce a revisar el tipo de datos contenidos en el dataset "race".
type(race)
pandas.core.groupby.generic.DataFrameGroupBy
-
Se generó un objeto DataFrameGroupBy, al llamar a grupos en este objeto (DataFrameGroupBy) devolverá los índices de cada grupo.
-
La función groupby() divide los datos en subgrupos y ahora pueden observar los índices de cada subgrupo esto muy útil, sin embargo, solo los índices no son suficientes. Necesitaremos ver los datos reales de cada grupo. La función get_group() permite realizar esto.
race.get_group('group B')
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | |
|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 |
| 5 | female | group B | associate's degree | standard | none | 71 | 83 | 78 |
| 6 | female | group B | some college | standard | completed | 88 | 95 | 92 |
| 7 | male | group B | some college | free/reduced | none | 40 | 43 | 39 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 969 | female | group B | bachelor's degree | standard | none | 75 | 84 | 80 |
| 976 | male | group B | some college | free/reduced | completed | 60 | 62 | 60 |
| 980 | female | group B | high school | free/reduced | none | 8 | 24 | 23 |
| 982 | male | group B | some high school | standard | completed | 79 | 85 | 86 |
| 991 | female | group B | some high school | standard | completed | 65 | 82 | 78 |
190 rows × 8 columns
- ¡Genial!, ¿No es así?
Tamaño de cada grupo
A través de la función size() se podrá saber con presición la cantidad de datos contenidos por cada grupo.
race.size()
race/ethnicity group A 89 group B 190 group C 319 group D 262 group E 140 dtype: int64
Bucles sobre cada grupo¶
- También se pueden recorrer los grupos a través de un bucle for, obteniendo el mismo resultado.
for name, group in race:
print(name, 'has', group.shape[0], 'data')
group A has 89 data group B has 190 data group C has 319 data group D has 262 data group E has 140 data
Agrupación por múltiples variables
En todos los ejemplos anteriores, los datos fueron agrupados a través de una sola variable, sin emabrgo, también es posible agrupar por múltiples variables. En en siguiente ejemplo se agruparán los datos "etnia" y "género", esto deberá devolver el número de datos de cada etnia separados por género.
df.groupby(['gender', 'race/ethnicity']).size()
gender race/ethnicity
female group A 36
group B 104
group C 180
group D 129
group E 69
male group A 53
group B 86
group C 139
group D 133
group E 71
dtype: int64
En el ejemplo anterior se agrupan los datos usando la función size(). También hay otras funciones agregadas, a continuación se muestra una lista de estas:
- suma()
- significa()
- Talla()
- contar()
- estándar()
- var()
- sem()
- min()
- mediana()
A continuación se realizarán algunas pruebas con algunas de estas funciones de agregación.
Uso de múltiples funciones agregadas
La forma en que se puede utilizar la función groupby() en múltiples variables, es haciendo uso de múltiples funciones agregadas, el siguiente ejemplo se agruparán los datos por "etnia" y se determinarán los valores máximos y mínimos a través de las funciones "max" y "min".
df.groupby('race/ethnicity').agg([np.max, np.min])
| gender | parental level of education | lunch | test preparation course | math score | reading score | writing score | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| amax | amin | amax | amin | amax | amin | amax | amin | amax | amin | amax | amin | amax | amin | |
| race/ethnicity | ||||||||||||||
| group A | male | female | some high school | associate's degree | standard | free/reduced | none | completed | 100 | 28 | 100 | 23 | 97 | 19 |
| group B | male | female | some high school | associate's degree | standard | free/reduced | none | completed | 97 | 8 | 97 | 24 | 96 | 15 |
| group C | male | female | some high school | associate's degree | standard | free/reduced | none | completed | 98 | 0 | 100 | 17 | 100 | 10 |
| group D | male | female | some high school | associate's degree | standard | free/reduced | none | completed | 100 | 26 | 100 | 31 | 100 | 32 |
| group E | male | female | some high school | associate's degree | standard | free/reduced | none | completed | 100 | 30 | 100 | 26 | 100 | 22 |
-
La función agregada se aplicó en todas las columnas, debido a que no se especificó ninguna.
-
Se realizará un ejemplo creando un DataFrame de puntuación mínima y máxima de matemáticas, lectura y escritura a través del siguiente código:
df.groupby('race/ethnicity')['math score', 'reading score', 'writing score'].agg([np.max, np.min])
| math score | reading score | writing score | ||||
|---|---|---|---|---|---|---|
| amax | amin | amax | amin | amax | amin | |
| race/ethnicity | ||||||
| group A | 100 | 28 | 100 | 23 | 97 | 19 |
| group B | 97 | 8 | 97 | 24 | 96 | 15 |
| group C | 98 | 0 | 100 | 17 | 100 | 10 |
| group D | 100 | 26 | 100 | 31 | 100 | 32 |
| group E | 100 | 30 | 100 | 26 | 100 | 22 |
Agrupando por múltiples variables y utilizando múltiples funciones agregadas.¶
-
Para demostrar esto, se agrupará por "etnia" y "género", además, se utilizarán dos funciones agregadas "min" y "max".
-
Se creeará un DataFrame que contiene la puntuación máxima y mínima en matemáticas, lectura y escritura para cada grupo separado por género.
df.groupby(['race/ethnicity', 'gender'])['math score', 'reading score', 'writing score'].agg([np.max, np.min])
| math score | reading score | writing score | |||||
|---|---|---|---|---|---|---|---|
| amax | amin | amax | amin | amax | amin | ||
| race/ethnicity | gender | ||||||
| group A | female | 92 | 34 | 100 | 43 | 97 | 41 |
| male | 100 | 28 | 96 | 23 | 92 | 19 | |
| group B | female | 97 | 8 | 97 | 24 | 96 | 23 |
| male | 94 | 30 | 96 | 24 | 92 | 15 | |
| group C | female | 96 | 0 | 100 | 17 | 100 | 10 |
| male | 98 | 27 | 100 | 28 | 95 | 27 | |
| group D | female | 98 | 26 | 100 | 31 | 100 | 32 |
| male | 100 | 39 | 97 | 34 | 99 | 34 | |
| group E | female | 100 | 32 | 100 | 34 | 100 | 38 |
| male | 100 | 30 | 100 | 26 | 100 | 22 | |
Diferentes funciones agregadas en diferentes columnas.
Se agrupará por "etnia", máximo y promedio de la puntuación de matemáticas. La mediana y mínima en la puntuación de lectura.
df.groupby('race/ethnicity').agg({'math score': ['max', 'mean'],
'reading score': ['median','min']})
| math score | reading score | |||
|---|---|---|---|---|
| max | mean | median | min | |
| race/ethnicity | ||||
| group A | 100 | 61.629213 | 64 | 23 |
| group B | 97 | 63.452632 | 67 | 24 |
| group C | 98 | 64.463950 | 71 | 17 |
| group D | 100 | 67.362595 | 71 | 31 |
| group E | 100 | 73.821429 | 74 | 26 |
- ¡Genial!, ¿No es así?... Sin embargo los nombres de las columnas no se muestran de manera clara, se pueden cambiar estos nombres de columnas de la siguiente manera.
math_read = df.groupby('race/ethnicity').agg({'math score': ['max', 'mean'], 'reading score': ['max', 'mean']})
math_read.columns = ['Max Math Score', 'Average Math Score', 'Max Reading Score', 'Average Reading Score' ]
math_read.head()
| Max Math Score | Average Math Score | Max Reading Score | Average Reading Score | |
|---|---|---|---|---|
| race/ethnicity | ||||
| group A | 100 | 61.629213 | 100 | 64.674157 |
| group B | 97 | 63.452632 | 97 | 67.352632 |
| group C | 98 | 64.463950 | 100 | 69.103448 |
| group D | 100 | 67.362595 | 100 | 70.030534 |
| group E | 100 | 73.821429 | 100 | 73.028571 |
- El mismo DataFrame, pero mucho más organizado.
Uso de funciones agregadas en columnas nominales.
En todos los ejemplos anteriores se utilizaron las funciones agregadas en columnas numéricas, sin embargo es posible hacer uso de funciones agregadas en algunas columnas nominales como "almuerzo" y "nivel de educación de los padres".
df.groupby(['race/ethnicity', 'gender']).agg({'lunch': pd.Series.mode, 'parental level of education': pd.Series.mode, 'math score':np.mean})
| lunch | parental level of education | math score | ||
|---|---|---|---|---|
| race/ethnicity | gender | |||
| group A | female | standard | some high school | 58.527778 |
| male | standard | some high school | 63.735849 | |
| group B | female | standard | high school | 61.403846 |
| male | standard | some college | 65.930233 | |
| group C | female | standard | associate's degree | 62.033333 |
| male | standard | high school | 67.611511 | |
| group D | female | standard | some college | 65.248062 |
| male | standard | some college | 69.413534 | |
| group E | female | standard | associate's degree | 70.811594 |
| male | standard | associate's degree | 76.746479 |
- Como se puede observar en el código anterior, la sintaxis es diferente para los datos nominales.
Aplicar una función en groupby().
- A continuación se procederá a calcular cuántos niños tienen padres con niveles de educación secundaria.
df.groupby(df['parental level of education'].apply(lambda x: 'high' in x)).size()
parental level of education False 625 True 375 dtype: int64
- Se procederá a dividir la columna "puntuación de matemáticas" en tres grupos, bajas, medias y altas para determinar la candidad de datos contenidos en dichos grupos
df.groupby(pd.qcut(x=df['math score'], q=3, labels=['low', 'average', 'high'])).size()
math score low 339 average 341 high 320 dtype: int64
- También es posible establecer los puntos de cortes, definiendo bajo, promedio y alto, de la siguiente manera.
df.groupby(pd.cut(df['math score'], [0, 40, 70, 100])).size()
math score (0, 40] 49 (40, 70] 559 (70, 100] 391 dtype: int64
Transformación con groupby().
A continuación se generará una nueva columna en el DataFrame "df" y se agregará una columna que contenga la diferencia de cada puntuación de matemáticas de la puntuación matemáticas media.
df['Distance From the Mean'] = df.groupby(['race/ethnicity', 'gender'])['math score'].transform(lambda x: x - x.mean())
df.head()
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | Distance From the Mean | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 | 10.596154 |
| 1 | female | group C | some college | standard | completed | 69 | 90 | 88 | 6.966667 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 | 28.596154 |
| 3 | male | group A | associate's degree | free/reduced | none | 47 | 57 | 44 | -16.735849 |
| 4 | male | group C | some college | standard | none | 76 | 78 | 75 | 8.388489 |
Observando el DataFrame, se puede ver que tiene una nueva columna al final llamada "Distancia de la media".
Filtros con groupby()
Se pueden filtrar los datos en función de determinadas condiciones para que los datos sean más significativos, por ejemplo se puede filtrar el grupo de "etnia" que tiene más de 100 filas de datos.
df_n = df.groupby('race/ethnicity').filter(lambda x: len(x) > 100)
El código anterior establece conservar los grupos que tienen una longitud de más de 100 filas de datos, se puede verificar esta longitud comparando con el DataFrame original "df" y el DataFrame filtrado "df_n".
print(len(df))
print(len(df_n))
1000 911
La longitud del DataFrame original es 1000, después de aplicar el filtro, la longitud del DataFrame se convierte en 911.
Mapeo de datos
Se puede mapear la puntuación promedio de lectura de cada grupo y generar una nueva columna con estos datos
df['New'] = df['race/ethnicity'].map(df.groupby(['race/ethnicity'])['reading score'].mean())
df.head()
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | Distance From the Mean | New | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | female | group B | bachelor's degree | standard | none | 72 | 72 | 74 | 10.596154 | 67.352632 |
| 1 | female | group C | some college | standard | completed | 69 | 90 | 88 | 6.966667 | 69.103448 |
| 2 | female | group B | master's degree | standard | none | 90 | 95 | 93 | 28.596154 | 67.352632 |
| 3 | male | group A | associate's degree | free/reduced | none | 47 | 57 | 44 | -16.735849 | 64.674157 |
| 4 | male | group C | some college | standard | none | 76 | 78 | 75 | 8.388489 | 69.103448 |
Observando el DataFrame, existe una nueva columna llamada "Nuevo" al final, que contiene la puntuación promedio de lectura del grupo correspondiente.
Visualización usando groupby().
A continuación se realizarán varias técnicas de visualización de grupos, primeramente se realizará un diagrama de barras con el nivel de educación de los padres.
plt.clf()
df.groupby('parental level of education').size().plot(kind='bar');
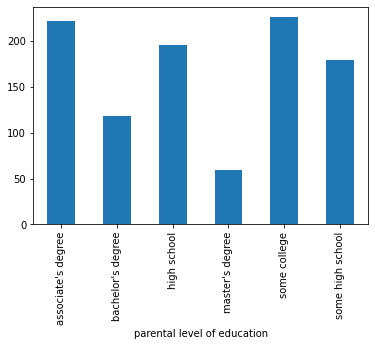
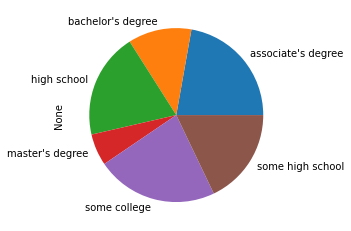
- Para realizar un gráfico circular o comúnmente llamado diagrama de torta, se escribe en tipo "pie" en lugar de "bar" en el código anterior, como se observa a continuación.
plt.clf()
df.groupby('parental level of education').size().plot(kind='pie');
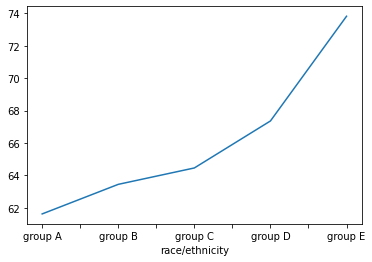
- Si no escribe ningún "tipo", el gráfico será una trama lineal simple, como ejemplo se procederá a graficar la puntuación promedio en matemáticas de cada grupo.
df.groupby('race/ethnicity')['math score'].mean().plot();
Conclusiones
En este artículo, se realizaron ejemplos que demuestran la gran utilidad de la función groupby() para:
- Agrupar y resumir los datos de muchas maneras diferentes,
- Uso de funciones agregadas,
- Transformación de datos,
- Filtro de datos,
- Mapeo de datos y,
- Visualización de datos.