10 de Noviembre del 2022 | Jhonatan Montilla
Este caso de estudio tiene como objetivo crear gráficos para respaldar el proceso de ciencia de datos. Las visualizaciones se pueden utilizar durante el análisis exploratorio, antes o después del procesamiento de datos, para construir gráficos estadísticos para el análisis de conjuntos de datos, identificar relaciones de variables o evaluar la distribución de datos.
Si bien Matplotlib se puede usar para este propósito, Seaborn es una biblioteca más eficiente y fácil de usar para crear gráficos estadísticos. Por lo tanto, tener la capacidad de crear visualizaciones usando cualquier herramienta es crucial.
Visite Jupyter Notebook para explorar los conceptos de visualización de datos con Seaborn. Nota: Las funciones clave, los resultados y los términos están en negrita para facilitar su comprensión.
import seaborn as sns
from scipy import stats
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
%matplotlib inline
sns.__version__
'0.12.2'
Experimente todo el potencial de Seaborn con sus conjuntos de datos incorporados.
Simplemente llame a get_dataset_names() para obtener una lista completa de todos los conjuntos de datos disponibles para experimentar.
sns.get_dataset_names()
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'dowjones', 'exercise', 'flights', 'fmri', 'geyser', 'glue', 'healthexp', 'iris', 'mpg', 'penguins', 'planets', 'seaice', 'taxis', 'tips', 'titanic']
Acceda a uno de los conjuntos de datos de la lista completa. Sumerjámonos en el conjunto de datos de iris de renombre mundial para esta demostración.
iris = sns.load_dataset("iris")
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
type(iris)
pandas.core.frame.DataFrame
La "función de resumen estadístico" en la biblioteca Seaborn es un método que proporciona un resumen rápido de la distribución de un conjunto de datos.
Este resumen generalmente incluye medidas como la media, la mediana, la moda y los cuartiles de los datos, y puede ayudarlo a comprender el patrón general y la distribución de los datos.
Al visualizar las estadísticas resumidas, puede identificar tendencias, valores atípicos y otras características importantes en sus datos, que pueden informar un análisis posterior y la toma de decisiones.
iris.describe()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
La función de descripción se puede aplicar a una variedad de tipos de gráficos en Seaborn, incluidos histogramas, diagramas de caja, diagramas de violín y otros, para ayudarlo a obtener rápidamente información sobre sus datos.
iris.columns
Index(['sepal_length', 'sepal_width', 'petal_length', 'petal_width',
'species'],
dtype='object')
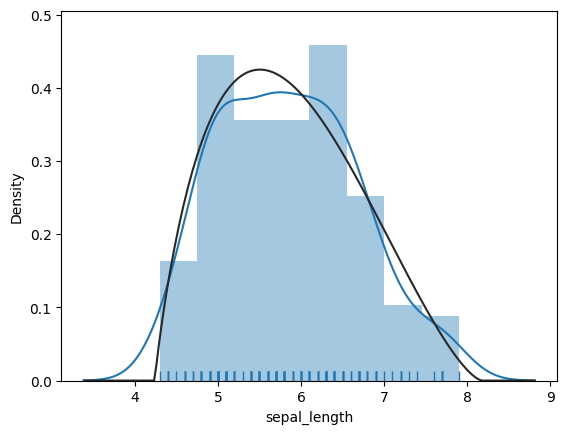
La gráfica de distribución de Seaborn, también conocida como gráfica de distribución univariada, se utiliza para visualizar la distribución de una sola variable. Para crear el gráfico, simplemente llame a la función distplot, pasando el nombre de la variable que desea visualizar, como 'sepal_length' del conjunto de datos del iris.
Además, puede especificar opciones como habilitar el gráfico de alfombra y ajustar el ajuste de los datos a sus preferencias.
El distplot proporciona una representación visual integral de la distribución de sus datos, incluida la tendencia central, la dispersión, la asimetría y cualquier posible valor atípico, lo que le permite obtener una comprensión más profunda de los datos”.
sns.distplot(iris.sepal_length, rug = True, fit = stats.gausshyper);
El gráfico conjunto de Seaborn es una poderosa herramienta para visualizar distribuciones bivariadas. Combina un gráfico de dispersión con histogramas de las variables en cada eje, lo que proporciona una visión integral de la relación entre dos variables.
Este gráfico único puede revelar información importante sobre la distribución de sus datos, incluida la presencia de relaciones positivas o negativas, la distribución de cada variable y la frecuencia de los puntos de datos.
sns.jointplot(x = "sepal_length", y = "petal_length", data = iris);
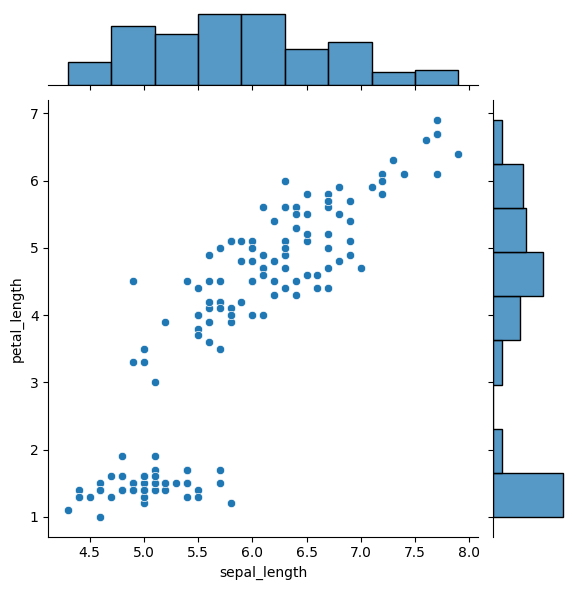
Con solo un comando simple, el gráfico conjunto proporciona una manera eficiente y efectiva de obtener información sobre las relaciones entre las variables en sus datos.
El hexágono de gráfico conjunto de Seaborn es una variación del gráfico conjunto, que presenta la distribución bivariada en un formato diferente.
En lugar de usar puntos para representar puntos de datos individuales, el gráfico hexadecimal usa hexágonos para agrupar y mostrar la densidad de los puntos de datos. Esto puede proporcionar una representación más clara de la relación entre dos variables, particularmente cuando hay una alta densidad de puntos de datos.
with sns.axes_style("white"):
sns.jointplot(
x = "sepal_length",
y = "petal_length",
data = iris,
kind = "hex",
color = "k"
);
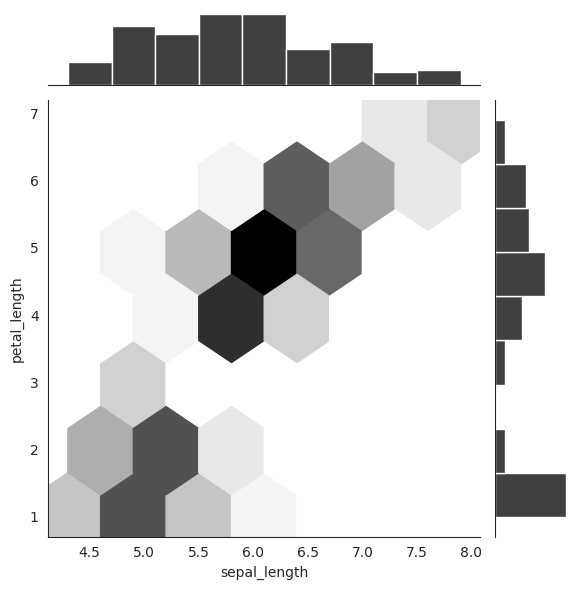
Además, el diseño del gráfico se puede personalizar fácilmente para adaptarse a sus necesidades específicas, lo que permite un mayor control sobre la apariencia y presentación de sus datos”.
El diagrama de densidad de Seaborn proporciona una representación alternativa de la distribución bivariada al cambiar la visualización de los puntos de datos a una estimación de densidad del kernel (KDE).
En lugar de puntos de datos individuales, la gráfica muestra la densidad estimada de los datos. Esto puede proporcionar una representación más fluida de la distribución de los datos y revelar patrones subyacentes que podrían no ser evidentes de inmediato en un diagrama de dispersión.
sns.jointplot(
x = "sepal_length",
y = "petal_length",
data = iris,
kind = "kde"
);
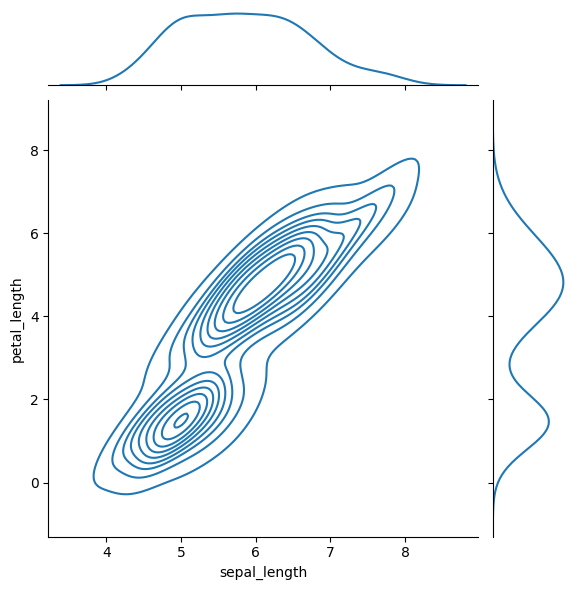
Además, los histogramas de los ejes también se transforman en gráficos de densidad, lo que proporciona una visión más completa de la distribución de cada variable.
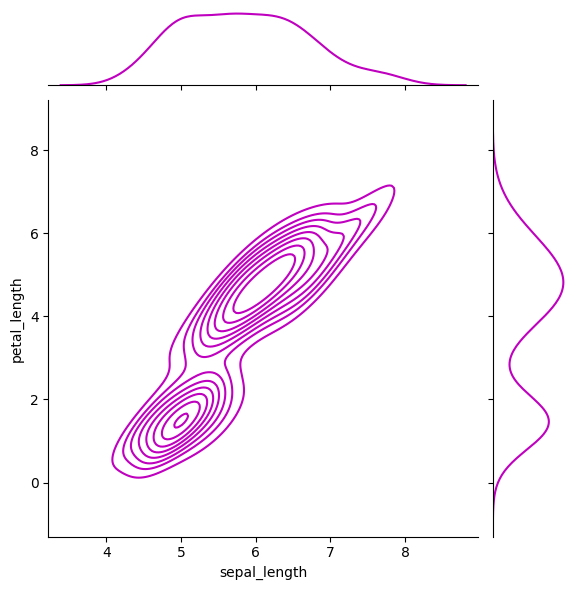
Para mostrar la versatilidad y la capacidad de Seaborn, aquí tenemos un ejemplo de cómo personalizar los parámetros de la gráfica conjunta de densidad anterior.
Con la capacidad de ajustar varios aspectos de la gráfica, como el color, el estilo del marcador y la apariencia de la gráfica, Seaborn proporciona una plataforma flexible y sólida para la visualización de datos, lo que le permite crear gráficas que comunican de manera efectiva los conocimientos contenidos en sus datos.
g = sns.jointplot(
x = "sepal_length",
y = "petal_length",
data = iris,
kind = "kde",
color = "m"
)
g.plot_joint(plt.scatter, c = "w", s = 30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0);
El diagrama de pares de Seaborn proporciona una vista integral de las relaciones entre todas las variables en un conjunto de datos.
Al llamar a la función pairplot y pasar el conjunto de datos, Seaborn crea automáticamente diagramas de dispersión e histogramas para todas las combinaciones de variables, mostrando sus relaciones en un solo gráfico.
sns.pairplot(iris);
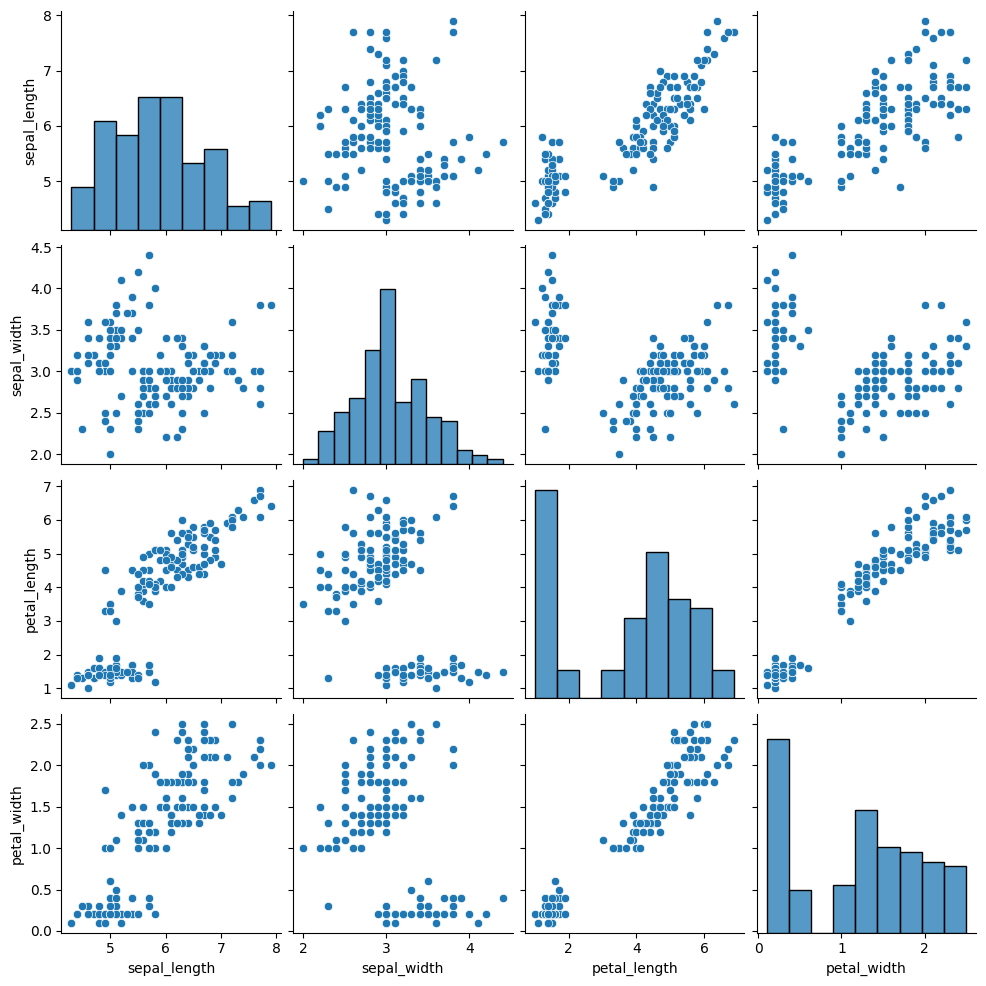
Este gráfico es una herramienta poderosa para obtener una comprensión general de la distribución de variables en sus datos y puede revelar rápidamente cualquier relación o patrón significativo.
Con una entrada mínima por parte del usuario, la función pairplot puede producir un gráfico altamente informativo que es valioso para el análisis exploratorio de datos.
Cargar conjunto de datos
Seaborn ofrece una amplia gama de opciones para visualizar datos. Para demostrar esto, exploraremos otro conjunto de datos, el conjunto de datos de "consejos", que proporciona una gran cantidad de información que espera ser visualizada.
tips = sns.load_dataset("tips")
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
Verificar el tipo de datos de sus variables en Pandas es importante por varias razones. Primero, lo ayuda a comprender la estructura de sus datos e identificar posibles errores o inconsistencias.
Por ejemplo, si espera que una columna contenga datos numéricos pero en su lugar se almacena como texto, esto puede causar problemas cuando intente realizar operaciones numéricas en esa columna.
type(tips)
pandas.core.frame.DataFrame
tips.describe()
| total_bill | tip | size | |
|---|---|---|---|
| count | 244.000000 | 244.000000 | 244.000000 |
| mean | 19.785943 | 2.998279 | 2.569672 |
| std | 8.902412 | 1.383638 | 0.951100 |
| min | 3.070000 | 1.000000 | 1.000000 |
| 25% | 13.347500 | 2.000000 | 2.000000 |
| 50% | 17.795000 | 2.900000 | 2.000000 |
| 75% | 24.127500 | 3.562500 | 3.000000 |
| max | 50.810000 | 10.000000 | 6.000000 |
La gráfica conjunta con regresión lineal en Seaborn es una poderosa herramienta para explorar la relación entre dos variables.
Al pasar el argumento "reg" al parámetro "tipo", el diagrama crea un diagrama de dispersión y ajusta una línea de regresión lineal a los datos, mostrando la fuerza de la relación entre las dos variables.
sns.jointplot(
x = "total_bill",
y = "tip",
data = tips,
kind = "reg"
);
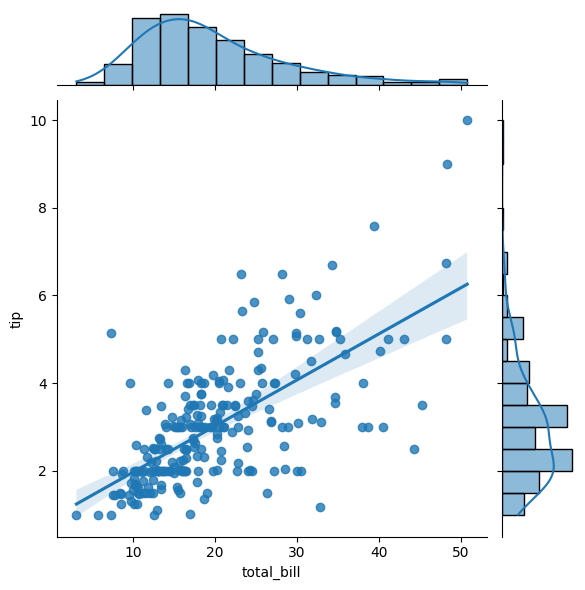
Además, el gráfico también incluye histogramas en los ejes para mostrar la distribución de cada variable y un gráfico de densidad para proporcionar una representación visual de la densidad de los puntos de datos.
Esta combinación de características hace que el gráfico conjunto con regresión lineal sea una herramienta increíblemente útil para comprender las relaciones en sus datos y explorar tendencias o patrones potenciales.
El lmplot en la biblioteca Seaborn es una herramienta poderosa para visualizar la relación entre dos variables en un diagrama de dispersión con una línea de regresión lineal ajustada.
A diferencia del gráfico conjunto, lmplot solo muestra el gráfico de dispersión y la línea de regresión, lo que permite un enfoque más claro en la relación entre las variables.
sns.lmplot(
x = "total_bill",
y = "tip",
data = tips
);
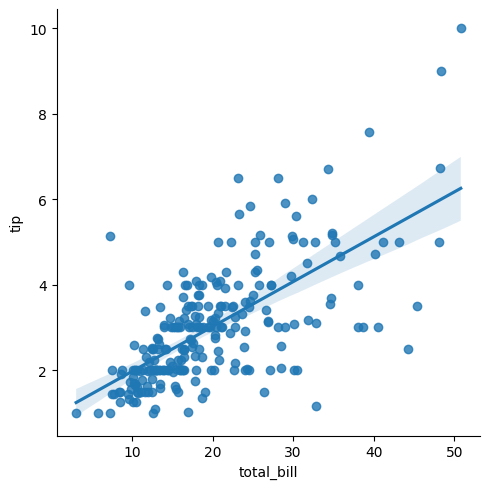
El lmplot también ofrece una gama de opciones de personalización, incluida la capacidad de controlar la apariencia de los puntos de datos y la línea de regresión.
Esta versatilidad hace que lmplot sea una herramienta útil para explorar y comprender las relaciones entre variables en sus datos y para presentar sus resultados de una manera clara y convincente.
sns.lmplot(
x = "size",
y = "tip",
data = tips,
x_jitter = .05
);
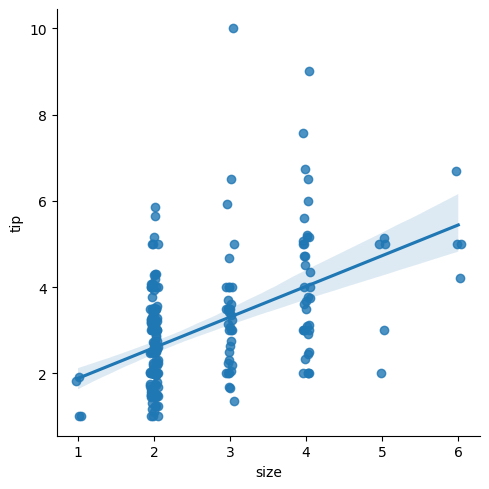
Este gráfico no solo muestra un diagrama de dispersión con una línea de regresión lineal ajustada, sino que también agrega límites superior e inferior a cada punto de datos, proporcionando una representación visual de la incertidumbre en los datos.
sns.lmplot(
x = "size",
y = "tip",
data = tips,
x_estimator = np.mean
);
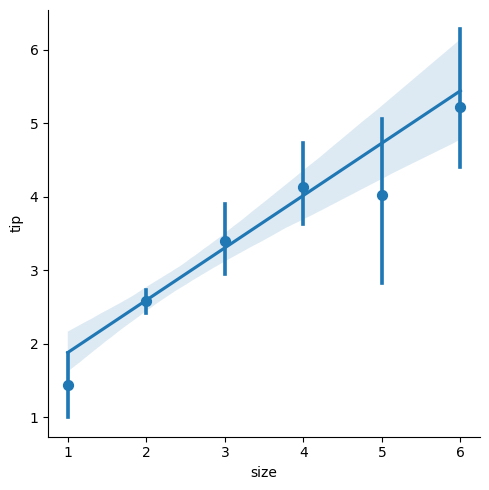
Al visualizar los límites, puede comprender mejor las relaciones entre las variables y tomar decisiones informadas sobre los datos y su análisis.
Carguemos otro conjunto de datos de Seaborn:
anscombe = sns.load_dataset("anscombe")
Podemos filtrar los datos del conjunto de datos para trazarlos en un gráfico, creando una especie de consulta.
sns.lmplot(
x = "x",
y = "y",
data = anscombe.query("dataset == 'II'"),
ci = None,
scatter_kws = {"s": 80}
);
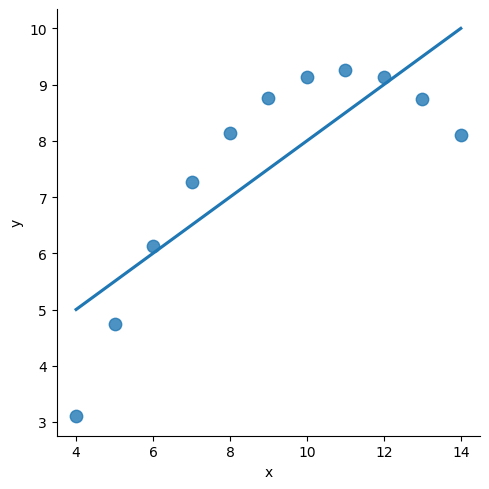
El ajuste de parámetros en Seaborn te permite personalizar la apariencia de tus gráficos, incluida la línea de regresión.
Al realizar ajustes en los parámetros, puede ajustar la visualización de sus datos, lo que facilita la comprensión de las relaciones entre las variables y la identificación de tendencias o patrones en los datos.
sns.lmplot(
x = "x",
y = "y",
data = anscombe.query("dataset == 'II'"),
order = 2,
ci = None,
scatter_kws = {"s": 80}
);
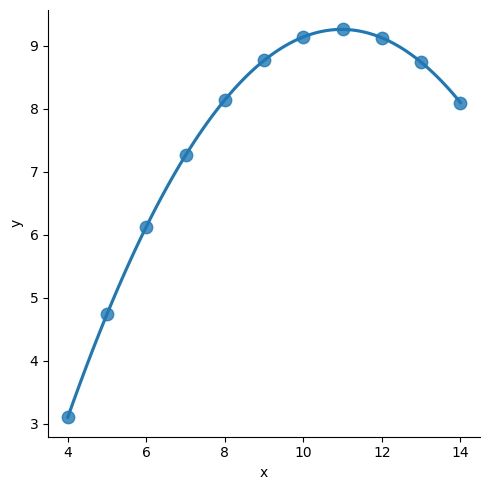
Ya sea que desee cambiar el color de la línea, el estilo del marcador o las etiquetas de los ejes, la capacidad de ajustar los parámetros le brinda la flexibilidad de presentar sus datos de la manera que mejor se adapte a su análisis.
La detección de valores atípicos es crucial, ya que ayuda a identificar puntos de datos que se desvían significativamente del patrón normal de los datos.
Al identificar estos valores atípicos, se puede obtener una comprensión más profunda de la distribución de los datos y tomar decisiones informadas basadas en los conocimientos.
sns.lmplot(
x = "x",
y = "y",
data = anscombe.query("dataset == 'III'"),
ci = None,
scatter_kws = {"s": 80}
);
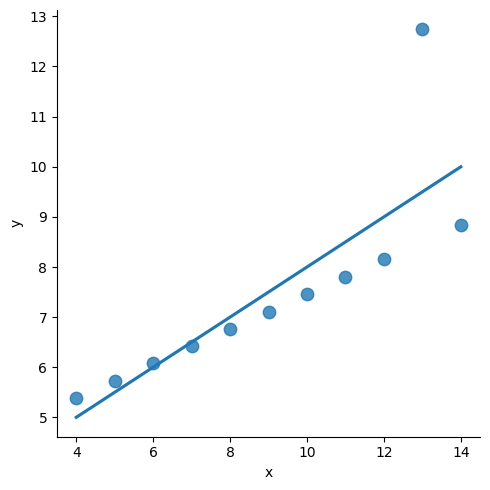
En Seaborn, la visualización de valores atípicos es un paso esencial en la exploración del conjunto de datos. Esto se puede lograr a través de varias técnicas, como diagramas de dispersión, diagramas de caja y otros.
Podemos visualizar una relación no lineal, donde el cambio en una variable no está proporcionalmente vinculado al cambio en otra variable.
sns.lmplot(
x = "total_bill",
y = "tip",
data = tips,
lowess = True
);
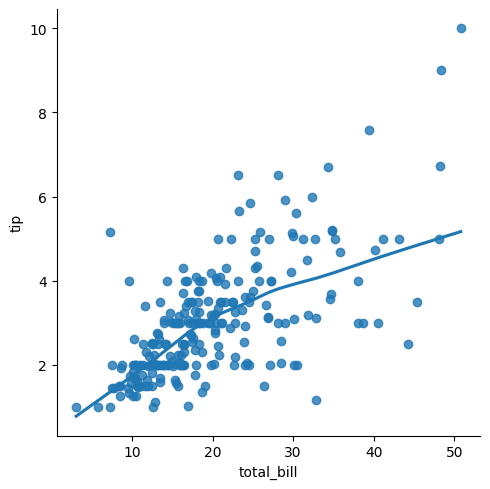
Otro lmplot que muestra varias piezas de información.
sns.lmplot(
x = "total_bill",
y = "tip",
hue = "smoker",
data = tips
);
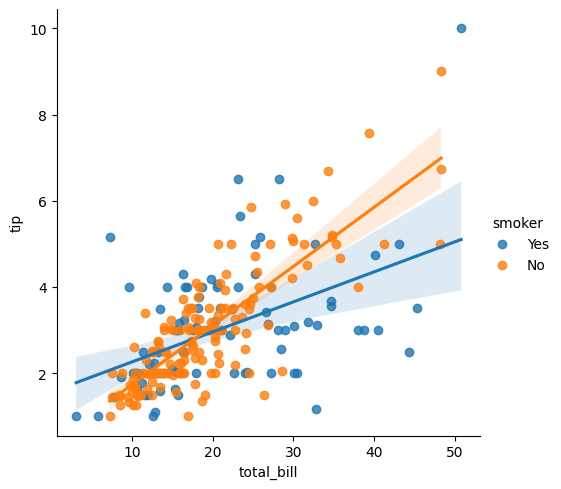
La importancia de personalizar las cartas en Seaborn radica en la capacidad de resaltar visualmente las diferencias entre las variables.
Al ajustar los parámetros, podemos crear gráficos que comuniquen de manera clara y efectiva la información que queremos transmitir.
sns.lmplot(
x = "total_bill",
y = "tip",
hue = "smoker",
data = tips, markers = ["o", "x"],
palette = "Set1"
);
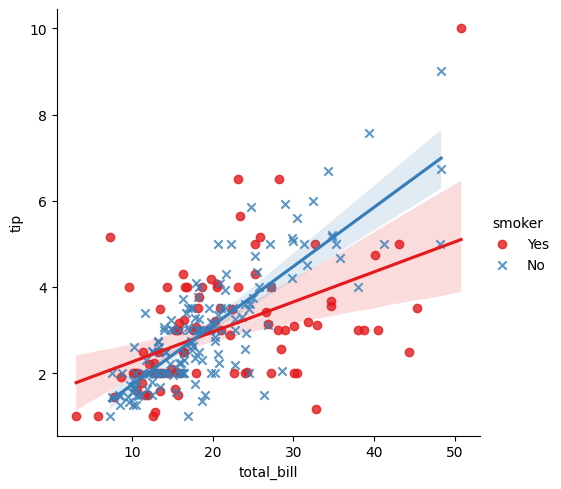
La personalización es una herramienta clave en el arsenal de visualización de datos y puede mejorar en gran medida el impacto de un gráfico.
Tenemos la opción de dividir el área de la parcela en múltiples secciones. El área completa de la gráfica se denomina área de la gráfica, y arriba tenemos un solo gráfico en el área de la gráfica, mientras que abajo tenemos dos gráficos en el área de la gráfica.
Por ejemplo, examinaremos la variable "punta" en el eje y. Usamos la misma variable para dos gráficos y hacemos un cambio en el parámetro “col”, dividiendo los gráficos en “total_bill” correspondiente a la hora de comer y cenar.
sns.lmplot(
x = "total_bill",
y = "tip",
hue = "smoker",
col = "time",
data = tips
);
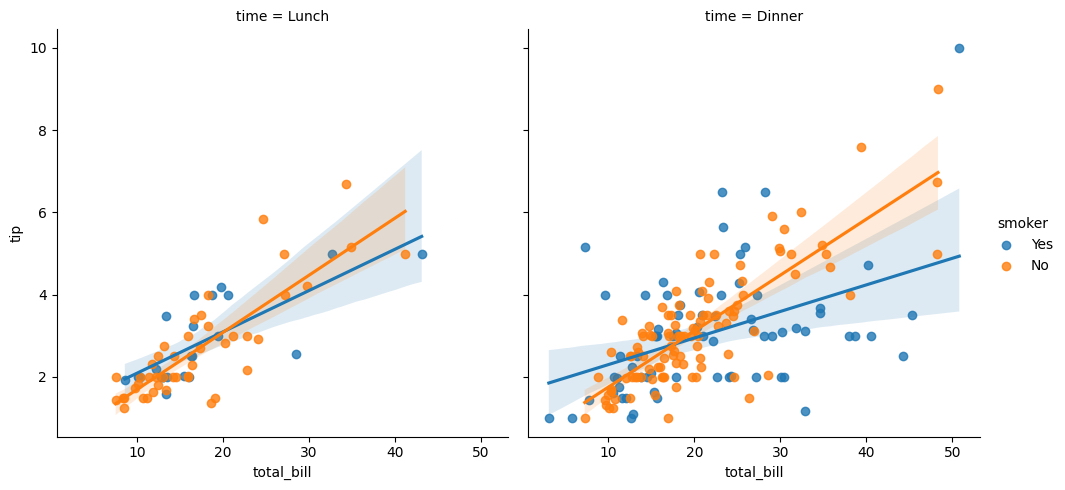
Con estos gráficos, tenemos la capacidad de hacer predicciones basadas en la información que se muestra. Al analizar la relación entre la propina y la factura total, podemos estimar la cantidad de propina esperada durante el almuerzo o la cena.
Al dividir el área en varios bloques, podemos comprender mejor las tendencias y patrones en los datos y hacer predicciones más informadas. Al incorporar múltiples variables, podemos construir una comprensión más completa de los datos y extraer información más significativa de ellos.
sns.lmplot(
x = "total_bill",
y = "tip",
hue = "smoker",
col = "time",
row = "sex",
data = tips
);
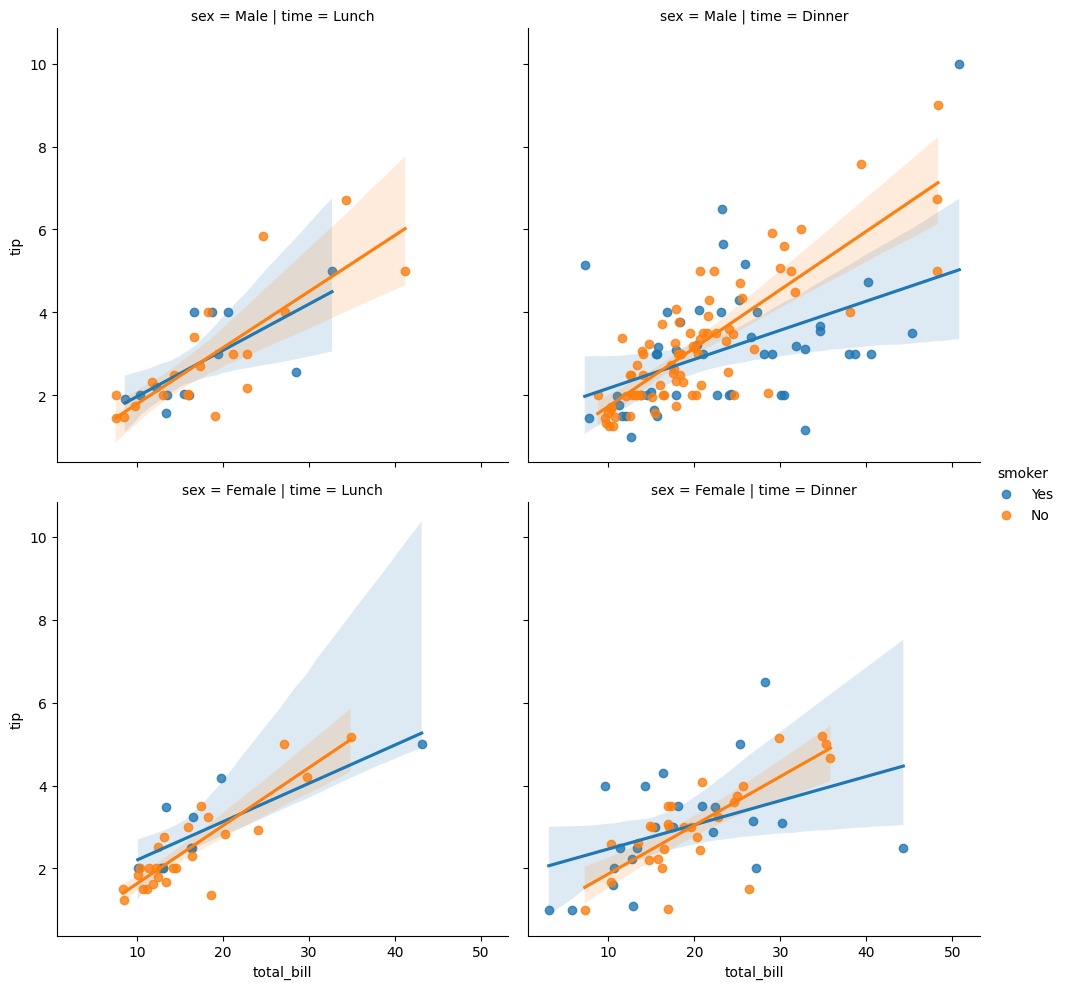
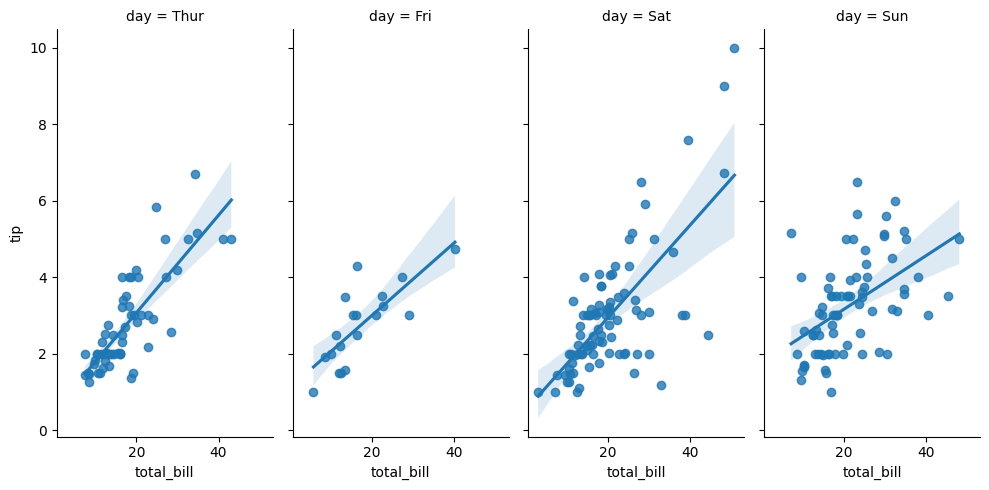
Podemos dividir aún más el área de la trama cambiando el parámetro col a días, creando así diferentes bloques de datos para cada día de la semana.
sns.lmplot(
x = "total_bill",
y = "tip",
col = "day",
data = tips,
col_wrap = 2
);
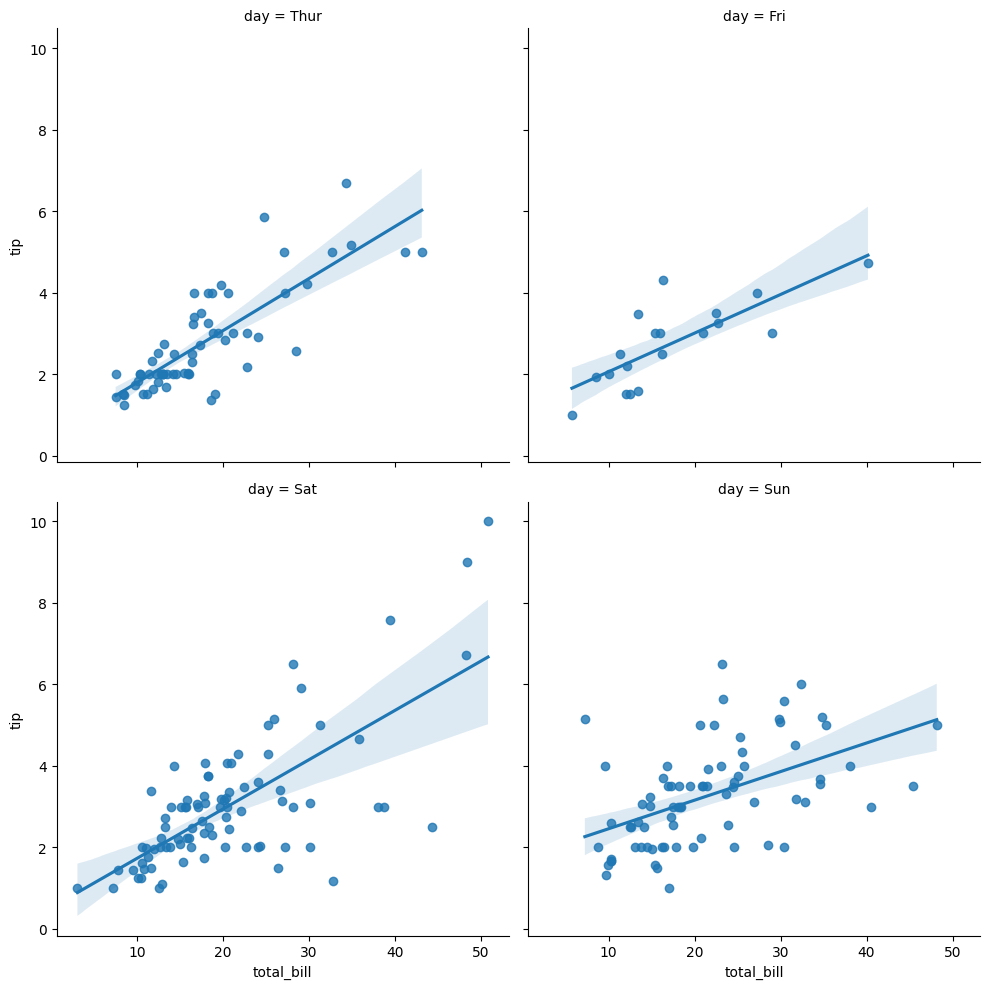
En lugar de tener varias parcelas apiladas verticalmente, ahora hemos cambiado la orientación para tenerlas una al lado de la otra.
Los días de la semana ahora están todos en una fila, proporcionando una representación visual horizontal con el cambio en los parámetros de col_wrap.
sns.lmplot(
x = "total_bill",
y = "tip",
col = "day",
data = tips,
aspect = .5
);
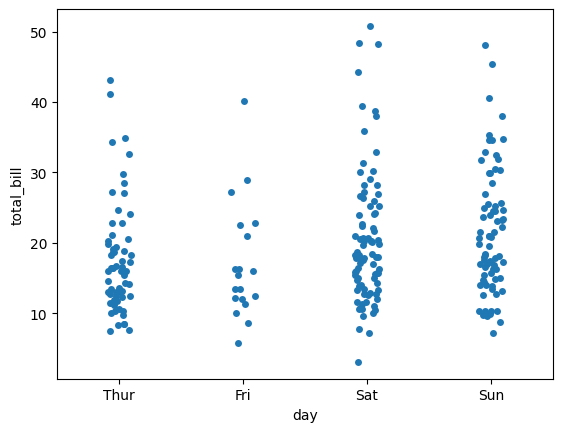
La representación de variables categóricas, o variables que contienen valores de cadena, es un aspecto importante de la visualización de datos.
Hasta ahora, hemos explorado gráficos para variables numéricas, pero es igualmente importante analizar visualmente las relaciones entre los datos categóricos y otras variables en nuestro conjunto de datos. diagrama de franjas
Ahora nuestro objetivo es identificar la factura total por día de la semana. Dado que el día de la semana es una variable categórica, debe representarse de manera diferente.
sns.stripplot(
x = "day",
y = "total_bill",
data = tips
);
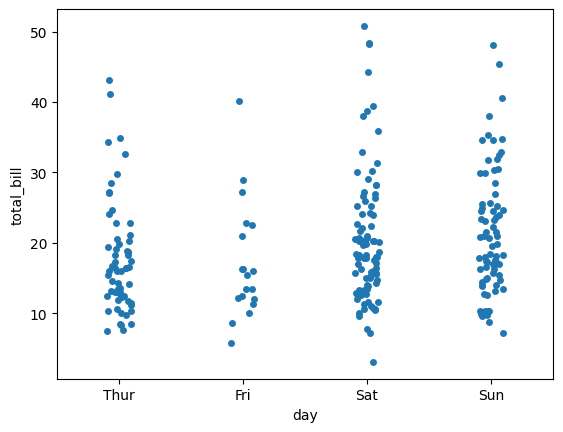
Podemos realizar ligeras personalizaciones en el Stripplot en seaborn. Con estas modificaciones, podemos crear un gráfico más compacto y conciso que el anterior.
sns.stripplot(
x = "day",
y = "total_bill",
data = tips,
jitter = True
);
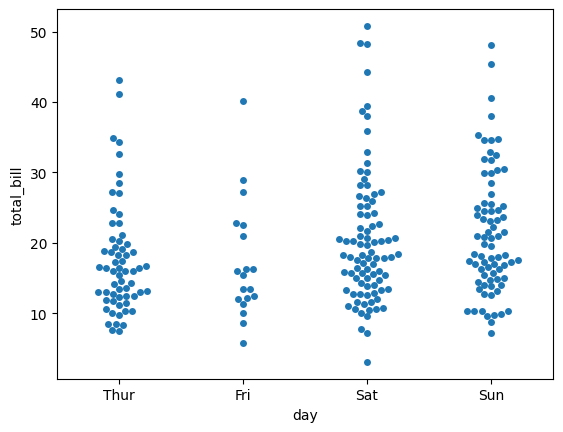
El Seaborn Swarmplot es similar al gráfico anterior, pero representa los puntos de datos de una manera que evita la superposición.
sns.swarmplot(
x = "day",
y = "total_bill",
data = tips
);
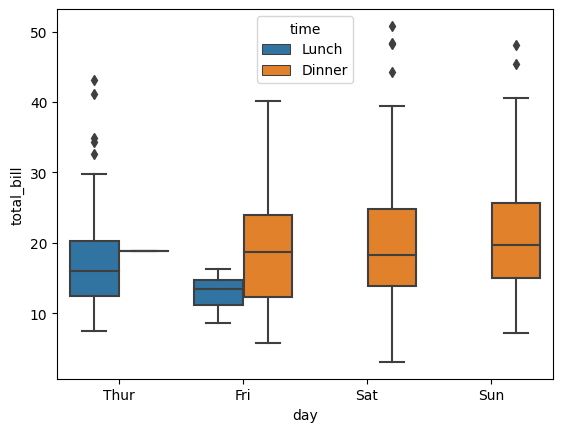
El diagrama de caja de Seaborn es un gráfico popular en estadística cuando se trata de variables categóricas. Muestra valores atípicos o valores que se desvían del patrón típico de la representación de datos.
sns.boxplot(
x = "day",
y = "total_bill",
hue = "time",
data = tips
);
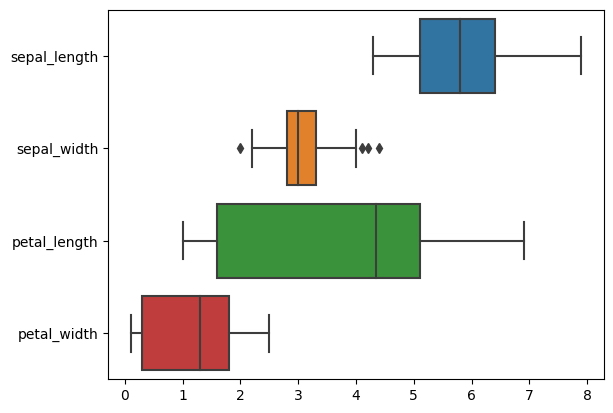
También podemos ajustar la orientación del diagrama de caja cambiándolo a un diseño horizontal.
sns.boxplot(
data = iris,
orient = "h"
);
El diagrama de violín es un gráfico útil en seaborn para visualizar la distribución de una variable.
Es una combinación de un diagrama de caja y un diagrama de densidad kernel, y muestra la densidad de los datos junto con los valores de rango y mediana.
sns.violinplot(
x = "total_bill",
y = "day",
hue = "time",
data = tips
);
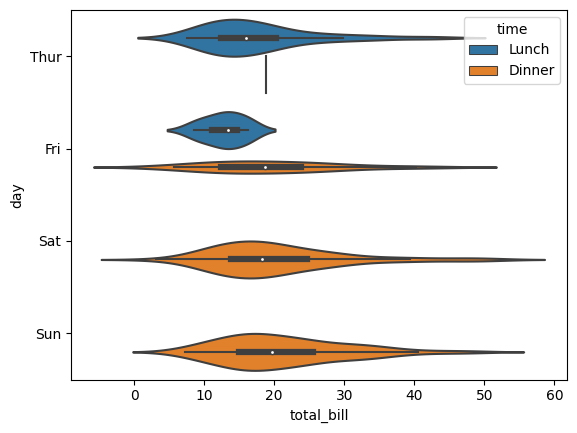
Este tipo de gráfico es particularmente útil para comprender la distribución de datos multimodales o para comparar las distribuciones de diferentes grupos o categorías.
Al usar la gráfica de violín, podemos obtener una visión más profunda de la distribución de una variable y tomar decisiones más informadas basadas en nuestro análisis.
Podemos personalizar un poco la trama del violín para hacer que la forma de los violines sea más estrecha.
sns.violinplot(
x = "total_bill",
y = "day",
hue = "time",
data = tips,
bw = .1,
scale = "count",
scale_hue = False
);
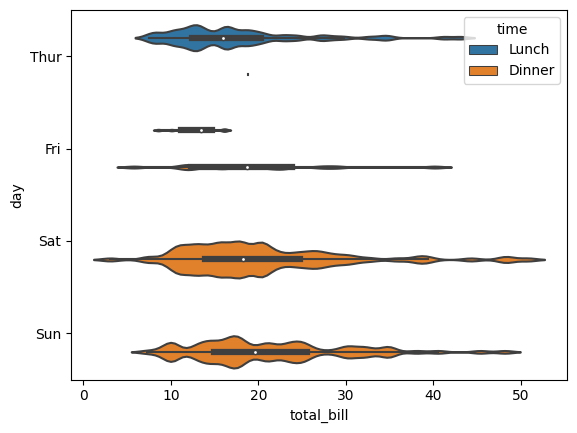
El diagrama de violín se puede mostrar en una orientación vertical.
sns.violinplot(
x = "day",
y = "total_bill",
hue = "sex",
data = tips,
split = True
);
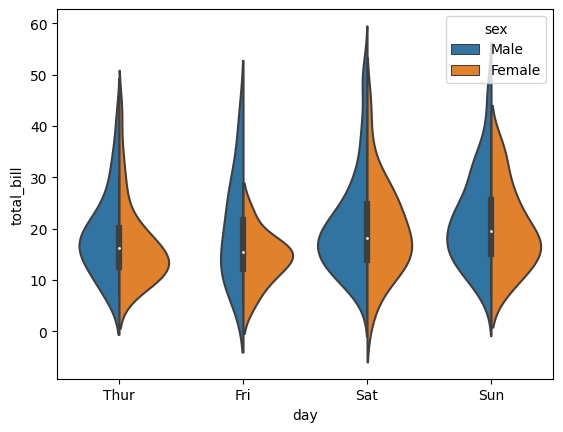
Otro gráfico comúnmente utilizado para representar variables categóricas es el gráfico de barras.
Los gráficos de barras son un gráfico de uso común para variables categóricas y proporcionan una representación visual de los datos a través de la altura de las barras.
sns.barplot(
x = "day",
y = "total_bill",
hue = "sex",
data = tips
);
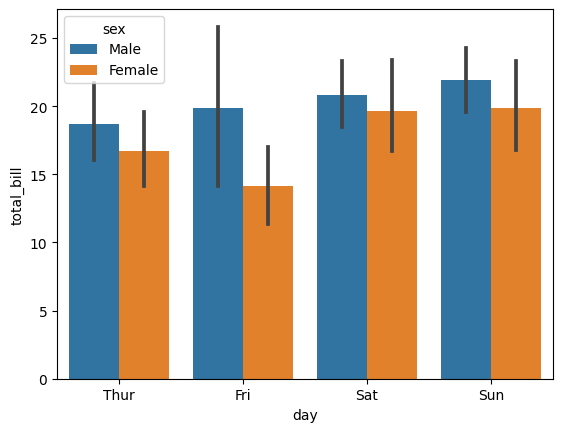
Ayudan a comparar rápidamente diferentes categorías e identificar tendencias y patrones. Además, los gráficos de barras permiten una fácil personalización y se pueden adaptar para adaptarse mejor a los datos que se analizan.
El gráfico de recuento es un gráfico que se utiliza para mostrar el recuento de elementos de cada categoría en una variable categórica. En este caso, se puede utilizar para mostrar el recuento de elementos para cada día de la semana.
sns.countplot(
x = "day",
data = tips,
palette = "Greens_d"
);
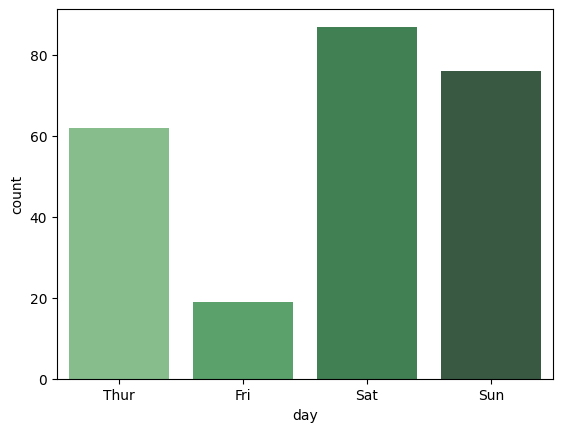
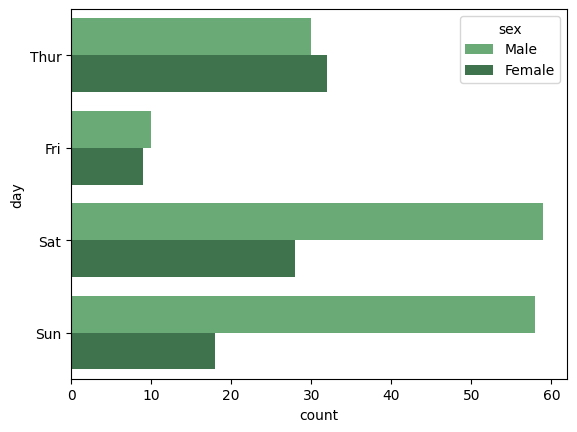
Podemos realizar cambios en el gráfico de recuento para mostrar el número de individuos por género por día de la semana en una orientación horizontal.
sns.countplot(
y = "day",
hue = "sex",
data = tips,
palette = "Greens_d"
);
Aquí vemos un ejemplo de contar con barras continuas, que se dividen en secciones para cada día de la semana.
f, ax = plt.subplots(figsize = (7, 3))
sns.countplot(
y = "day",
data = tips,
color = "c"
);
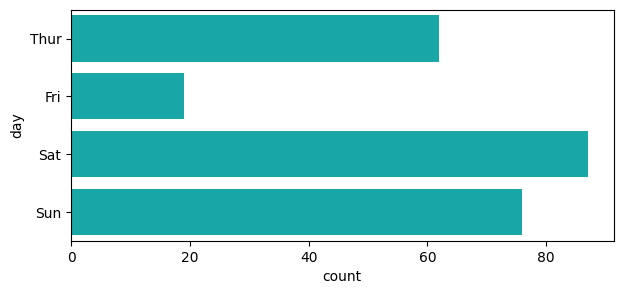
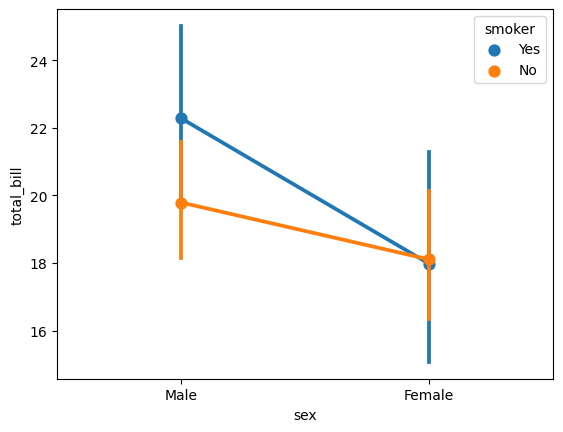
El diagrama de puntos es otro tipo de gráfico que se puede usar para representar variables categóricas al mostrar la relación entre el género y el conteo total.
sns.pointplot(
x = "sex",
y = "total_bill",
hue = "smoker",
data = tips
);